I'm developing a python script to scrape data from a specific site:
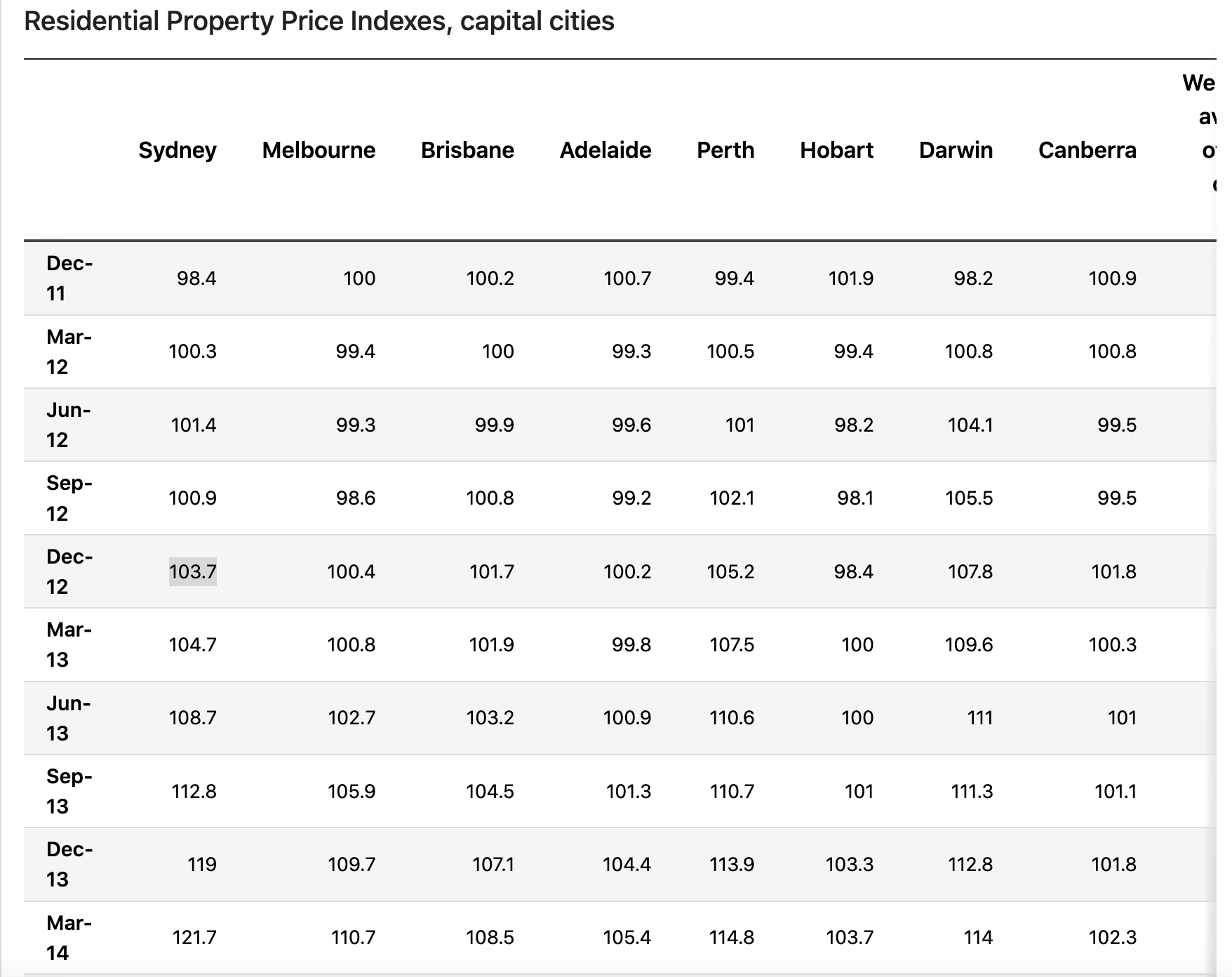
I would like to scrap the above data and have tried this way
import requests
from bs4 import BeautifulSoup
res=requests.get("https://www.abs.gov.au/statistics/economy/price-indexes-and-inflation/residential-property-price-indexes-eight-capital-cities/latest-release")
soup=BeautifulSoup(res.text,"html.parser")
table=soup.find_all('table', class_='chart-data-table has-chart responsive-enabled double-headers')
print(table.get_text())
Once I tried to run it, error occurred:
Traceback (most recent call last):
File "/Users/ryanngan/PycharmProjects/Webscraping/seek.py", line 6, in <module>
print(table.get_text())
File "/Users/ryanngan/PycharmProjects/Webscraping/venv/lib/python3.9/site-packages/bs4/element.py", line 2289, in __getattr__
raise AttributeError(
AttributeError: ResultSet object has no attribute 'get_text'. You're probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?
How can I scrap the above data in the website? Am I referring to a wrong tag? Thank you very much.
CodePudding user response:
The easiest way is to use pandas.read_html:
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = "https://www.abs.gov.au/statistics/economy/price-indexes-and-inflation/residential-property-price-indexes-eight-capital-cities/latest-release#residential-property-price-indexes"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
table = soup.select_one(
'table:has(caption:-soup-contains("Residential Property Price Indexes, capital cities"))'
)
# parse the table manually or use pandas.read_html
df = pd.read_html(str(table))[0]
print(df)
Prints:
Unnamed: 0 Sydney Melbourne Brisbane Adelaide Perth Hobart Darwin Canberra Weighted average of eight capital cities
0 Dec-11 98.4 100.0 100.2 100.7 99.4 101.9 98.2 100.9 99.4
1 Mar-12 100.3 99.4 100.0 99.3 100.5 99.4 100.8 100.8 100.0
2 Jun-12 101.4 99.3 99.9 99.6 101.0 98.2 104.1 99.5 100.4
3 Sep-12 100.9 98.6 100.8 99.2 102.1 98.1 105.5 99.5 100.2
4 Dec-12 103.7 100.4 101.7 100.2 105.2 98.4 107.8 101.8 102.4
5 Mar-13 104.7 100.8 101.9 99.8 107.5 100.0 109.6 100.3 103.1
6 Jun-13 108.7 102.7 103.2 100.9 110.6 100.0 111.0 101.0 105.7
...
Manual parsing:
header = [th.text for th in table.thead.select("th")]
print(*header, sep="\t")
for row in table.tbody.select("tr"):
tds = [td.text for td in row.select("th, td")]
print(*tds, sep="\t")
CodePudding user response:
find_all() returns an array of elements. You should go through all of them and select that one you are need. And than call get_text()
for el in table:
print el.get_text()