I have a file with data of multiple transaction status, refer "FILE PIC". Now I want to get different dataframes for all transaction status without total of third column. The string in first column are fixed for all the transaction status and row below the string are column names.
By the strings, I want to differentiate the dataframes, for reference see required output below.
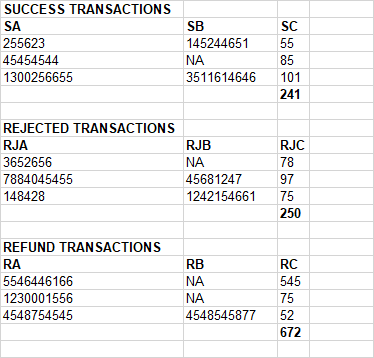
File data
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
241
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
250
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
672
Output Required
SUCCESS TRANSACTIONS DF
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
REJECTED TRANSACTIONS DF
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
REFUND TRANSACTIONS DF
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
CodePudding user response:
Let's prepare the data:
import pandas as pd
from io import StringIO
data = '''
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
241
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
250
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
672
'''
df = pd.read_csv(StringIO(data), sep='\s\s ', engine='python', names=[*'abc'])
I'm not sure if this data are exactly the same as the one on your side. So be careful with the code below. Anyway, that's what you posted, so be it.
The common way to split such construction is like this:
- extract some pattern as a marker of a starting row;
- use
cumsummethod to mark rows of a contiguous group with the same number; - use these numbers to identify groups in
groupby.
Here's how it can look in code:
grouper = df['a'].str.endswith('TRANSACTIONS').cumsum()
groups = {}
for _, gr in df.groupby(grouper):
name = gr.iloc[0, 0]
groups[name] = (
gr[1:-1] # skip the very first row with a general name, and the last one with total
.T.set_index(gr.index[1]).T # use the row under the general name as a column names
.reset_index(drop=True) # drop old indexes
.rename_axis(columns='')
)
for name, group in groups.items():
display(group.style.set_caption(name))
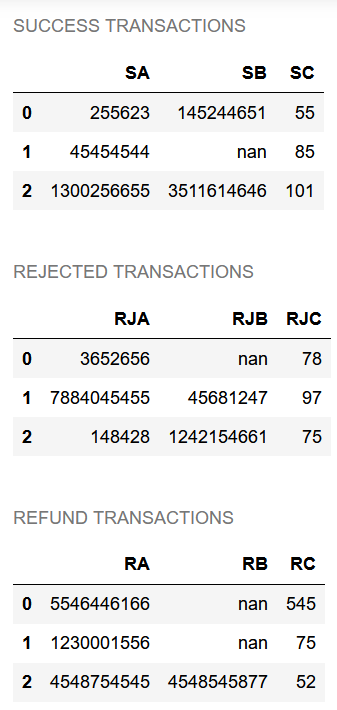
The output:
CodePudding user response:
One way to parse file into dataframes.
from io import StringIO
def parse_files(filenm):
' Parse files into dataframes based upon transaction type '
with open(filenm, 'r') as f:
transaction = ""
dfs = {} # Resulting dataframes
for line in f:
line = line.strip()
if line:
# only process non-blank lines
if not transaction:
# Must be on the first row of lines for DataFrame
transaction = line " DF"
data = []
elif len(line.split()) > 1:
# Multi column row
data.append(line)
else:
# Single column row
# Must be row with total
# Generate Dataframe from accumulated data
data = '\n'.join(data)
df = pd.read_csv(StringIO(data), sep = '\s ', engine = 'python')
dfs[transaction] = df
transaction = ''
return dfs
Usage
# Parse file into dataframe
dfs = parse_files('test.txt')
# Set to show float numbers rather than exponetiation
pd.set_option('display.float_format', lambda x: '%.0f' % x)
# Show dataframes
for category, df in dfs.items():
print(f'{category}')
print(df.round(5))
print()
Output
SUCCESS TRANSACTIONS DF
SA SB SC
0 255623 145244651 55
1 45454544 NaN 85
2 1300256655 3511614646 101
REJECTED TRANSACTIONS DF
RJA RJB RJC
0 3652656 NaN 78
1 7884045455 45681247 97
2 148428 1242154661 75
REFUND TRANSACTIONS DF
RA RB RC
0 5546446166 NaN 545
1 1230001556 NaN 75
2 4548754545 4548545877 52
CodePudding user response:
If the data are stored in string ds:
print('\n'.join(['\n'.join(ta.split('\n')[:-1]) for ta in ds.split(\n\n)]))
prints what you have requested.
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
Below the entire code printing the output above:
data_as_string = """\
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
241
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
250
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
672"""
ds = data_as_string
nl = '\n'
dnl = '\n\n'
# with finally:
print(nl.join([nl.join(ta.split(nl)[:-1]) for ta in ds.split(dnl)]))