I have a data frame like this:
mydf <- data.frame(ID, age, gender, diagnosis, A1, A2, A3)
mydf
ID age gender diagnosis A1 A2 A3
a 22 female 1 4 12 23
b 34 male 2 5 15 33
c 55 female 2 12 46 45
d 55 female 1 45 34 66
e 45 male 1 33 56 32
A1, A2, A3 refer to the questions in my test and the numbers below represent the score that an ID took from that question. "1" and "2" under the diagnosis represent whether the participant has the diagnosis or not.
What I want is to get mean scores for each question and make a bar plot showing the difference across diagnosis groups.
I calculated the mean for question columns like this:
mydf <- rbind(mydf, "mean" = round(colMeans(mydf[,5:7], na.rm = TRUE), 2))
mydf
ID age gender diagnosis A1 A2 A3
a 22.0 female 1 4.0 12.0 23.0
b 34.0 male 2 5.0 15.0 33.0
c 55.0 female 2 12.0 46.0 45.0
d 55.0 female 1 45.0 34.0 66.0
e 45.0 male 1 33.0 56.0 32.0
19.8 32.6 39.8 19.8 32.6 39.8 19.8
So, it added a new row but although I choose only question columns, I don't know why it also gave a mean for Id, age, gender, and diagnosis columns too.
And, I am not sure which steps should I take after this point to make a bar chart for the mean score for each question across diagnoses something like in the picture.
CodePudding user response:
This should work:
library( tidyverse )
### Create tibble
mydf <- tibble( ID = c( "a", "b", "c", "d", "e" ),
age = c( 22, 34, 55, 55, 45 ),
gender = c( "female", "male", "female", "female", "male" ),
diagnosis = c( 1, 2, 2, 1, 1 ),
A1 = c( 4, 5, 12, 45, 33 ),
A2 = c( 12, 15, 46, 34, 56 ),
A3 = c( 23, 33, 45, 66, 32 ) )
### Caclulate the mean for each item within diagnosis group
mydf <- mydf %>% group_by( diagnosis ) %>% mutate( A1_mean = mean( A1, na.rm = T ) ) %>%
mutate( A2_mean = mean( A2, na.rm = T ) ) %>% mutate( A3_mean = mean( A3, na.rm = T ) )
### Reshape from wide to long format
mydf2 <- pivot_longer( mydf, cols = c( A1_mean, A2_mean, A3_mean ), names_to = "question" )
mydf2
### Plot data
ggplot( mydf2, aes( x = factor( question ), y = value, fill = factor( diagnosis ) ) )
geom_bar( position = "dodge", stat = "identity" ) scale_fill_brewer( palette = "Set2" )
scale_y_continuous( expand = expansion( mult = c( 0,.05 ) ) )
scale_x_discrete( labels = c( "A1_mean" = "A1", "A2_mean" = "A2", "A3_mean" = "A3" ) )
theme( legend.position = "bottom" ) ggtitle( "Mean for each Question by Diagnosis Group" )
xlab( "Question" ) ylab( "Mean" ) labs( fill = "Diagnosis" )
CodePudding user response:
Thanks a lot to @David!
Inspired by him, this code solved my question.
#choose diagnosis and question columns and calculate the mean score for columns
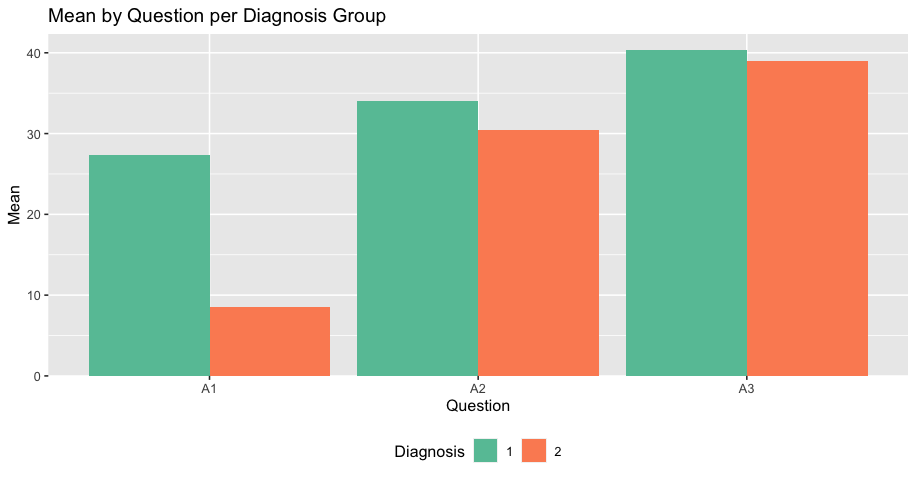
mydf2 <- mydf %>% select(diagnosis, A1, A2, A3) %>% group_by(diagnosis)%>% summarise_if(is.numeric, mean, na.rm=TRUE)
and this is what I get:
# A tibble: 2 x 4
diagnosis A1 A2 A3
<chr> <dbl> <dbl> <dbl>
1 27.3 34 40.3
2 8.5 30.5 39
and then reshaped the tibble similarly to David's code with tidyverse:
mydf2 <- mydf2 %>%
pivot_longer(!diagnosis, names_to = "Questions", values_to = "Values")
mydf2
# A tibble: 6 x 3
diagnosis Questions Values
<chr> <chr> <dbl>
1 A1 27.3
1 A2 34
1 A3 40.3
2 A1 8.5
2 A2 30.5
2 A3 39
Then made the graph as David showed:
ggplot( mydf2, aes( x = Questions, y = Values, fill = diagnosis ) )
geom_bar( position = "dodge", stat = "identity" ) scale_fill_brewer( palette = "Set2" )
scale_y_continuous( expand = expansion( mult = c( 0,.05 ) ) )
theme( legend.position = "bottom" ) ggtitle( "Mean for each Question by Diagnosis Group" )
xlab( "Question" ) ylab( "Mean" ) labs( fill = "Diagnosis" )
and got the graph I wanted: