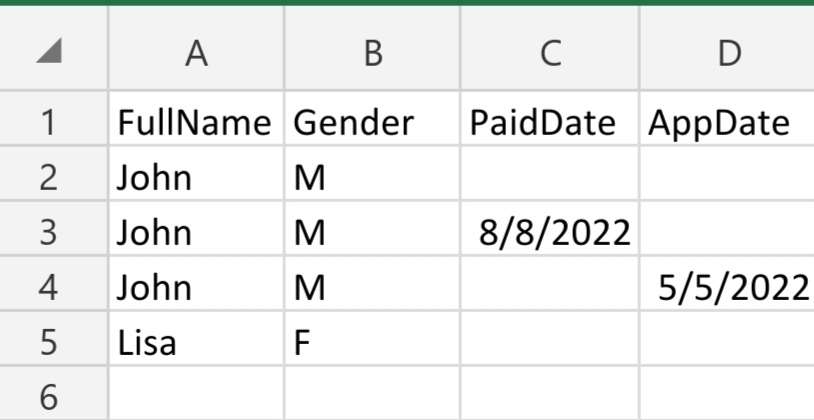
I have this table in SQL where I would like to delete duplicate values if paidDate or AppDate are not populated.
With the sample below, I would only like to delete the first John row, because neither paidDate nor AppDate are not populated for that row, but I would like to keep Lisa in this table because it is not a duplicate.
Is there a way to do this?
CodePudding user response:
Just an alternative approach, using a CTE and a windowed functions:
WITH CTE AS(
SELECT FullName,
PaidDate,
AppDate,
COUNT(CASE WHEN PaidDate IS NOT NULL OR AppDate IS NOT NULL THEN 1 END) AS C
FROM dbo.YourTable)
DELETE FROM CTE
WHERE C > 0
AND PaidDate IS NULL
AND AppDate IS NULL;
CodePudding user response:
DELETE m1
FROM MyTable m1
LEFT JOIN MyTable m2 ON m2.FullName = m1.FullName
AND (m2.PaidDate IS NOT NULL or m2.AppDate IS NOT NULL)
WHERE m1.PaidDate IS NULL AND m1.AppDate IS NULL
AND m2.FullName IS NOT NULL
or
DELETE FROM MyTable m1
WHERE m1.PaidDate IS NULL AND m1.AppDate IS NULL
AND NOT EXISTS(
SELECT 1
FROM MyTable
WHERE FullName = m1.FullName AND (AppDate IS NOT NULL OR PaidDate IS NOT NULL)
)
The second NOT EXISTS approach tends to run a little faster, but my own history makes me much faster at writing/maintaining the first exclusion join option.
I really hate using FullName as a key like this. It's rare for a dateset to ensure values like full name are distinct between entities. It's very common to find legitimate duplicate names.