When we have to convert a Spark Dataframe to Dataset. We generally use case class. It means we are converting a Row of un-Type to Type. Example:
case class MyData (Name: String, Age: Int)
import spark.implicits._
val ds = df.as[MyData]
Let say I have one RDD & mapping with a case class then converting to dataframe. Why at the end dataframe showing Dataset[Row].
case class MyData(Name: String, Age: Int)
object learning extends App{
val spark = SparkSession.builder()
.appName("dataFrames")
.config("spark.master", "local")
.getOrCreate()
val data = Seq(("A",100),("B",300),("C",400))
val rdd = spark.sparkContext.parallelize(data)
val rddNew = rdd.map( x => MyData(x._1,x._2) )
val newDataFrame = spark.createDataFrame(rddNew)
newDataFrame.show()
}
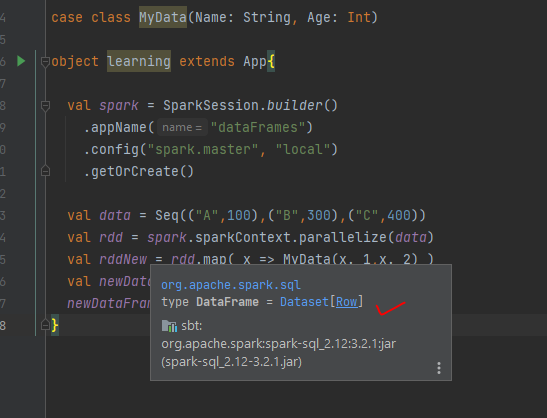
Why not this dataframe is showing as Dataset[MyData]?
CodePudding user response:
This is because the return type of spark.createDataFrame is DataFrame which is equivalent to Dataset[Row].
If you want the return type to be Dataset[MyData], use spark.createDataset:
import spark.implicits._
val newDataset: Dataset[MyData] = spark.createDataset[MyData](rddNew)