I want to remove elements from an original list tokens which are at specified indices indices_to_remove and also keep the record of the deleted records but the problem is that when I have two indices to remove and I remove the record from first index, the second record cannot be removed correctly. Any idea on how to address this?
deleted_records = []
tokens = ['hi', 'what', 'is', 'there']
indices_to_remove = [2,3]
for index in indices_to_remove:
deleted_tokens.append(tokens[index])
del tokens[index]
CodePudding user response:
Its generally not a good idea to modify a collection while iterating it.
So, the simplest way is to maintain two lists to gather the results like this
removed, retained = [], []
tokens = ['hi', 'what', 'is', 'there']
indices_to_remove = {2, 3} # Set for faster lookups
for idx, token in enumerate(tokens):
selected_list = removed if idx in indices_to_remove else retained
selected_list.append(token)
print(removed, retained)
CodePudding user response:
List comprehensions are fast.
deleted = [tokens[i] for i in sorted(indices_to_remove)]
tokens = [e for i, e in enumerate(tokens) if i not in indices_to_remove]
But first, given some ambiguity in the question, and for the sake of performance, some assumptions:
indices_to_removeis aset(O(1) membership test).- The OP wants
deletedto be in the same order as in the initialtokenslist. - (Obviously) all indices are valid (
0 <= i < len(tokens)for alli). If not, well, you'll get anIndexError.
Speed test
import random
from math import isqrt
def gen(n):
tokens = [f'x-{i}' for i in range(n)]
indices_to_remove = set(random.sample(range(n), isqrt(n)))
return tokens, indices_to_remove
# our initial solution
def f0(tokens, indices_to_remove):
deleted = [e for i, e in enumerate(tokens) if i in indices_to_remove]
tokens = [e for i, e in enumerate(tokens) if i not in indices_to_remove]
return deleted, tokens
# improved version, based on a comment by @KellyBundy
def f1(tokens, indices_to_remove):
deleted = [tokens[i] for i in sorted(indices_to_remove)]
tokens = [e for i, e in enumerate(tokens) if i not in indices_to_remove]
return deleted, tokens
# @thefourtheye version
def f4(tokens, indices_to_remove):
removed, retained = [], []
for idx, token in enumerate(tokens):
selected_list = removed if idx in indices_to_remove else retained
selected_list.append(token)
return removed, retained
# modified Kelly_1 to comply with our assumptions
# the original is certainly even faster, but modifies
# tokens in place, so harder to benchmark
def Kelly_1(tokens, indices_to_remove):
tokens = tokens.copy()
indices_to_remove = sorted(indices_to_remove)
return [*map(tokens.pop, reversed(indices_to_remove))][::-1], tokens
Test:
tokens, indices_to_remove = gen(1_000_000)
%timeit f0(tokens, indices_to_remove)
134 ms ± 603 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit f4(tokens, indices_to_remove)
111 ms ± 34.8 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit f1(tokens, indices_to_remove)
76.9 ms ± 194 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Here is a benchmark to see the runtime differences over scale (length of tokens; note, the number of tokens to delete is always ~sqrt(n):
import perfplot
perfplot.show(
setup=gen,
kernels=[f0, f1, f4, Kelly_1],
n_range=[2**k for k in range(3, 20)],
relative_to=1,
xlabel='n elements',
equality_check=lambda x, y: x == y,
)
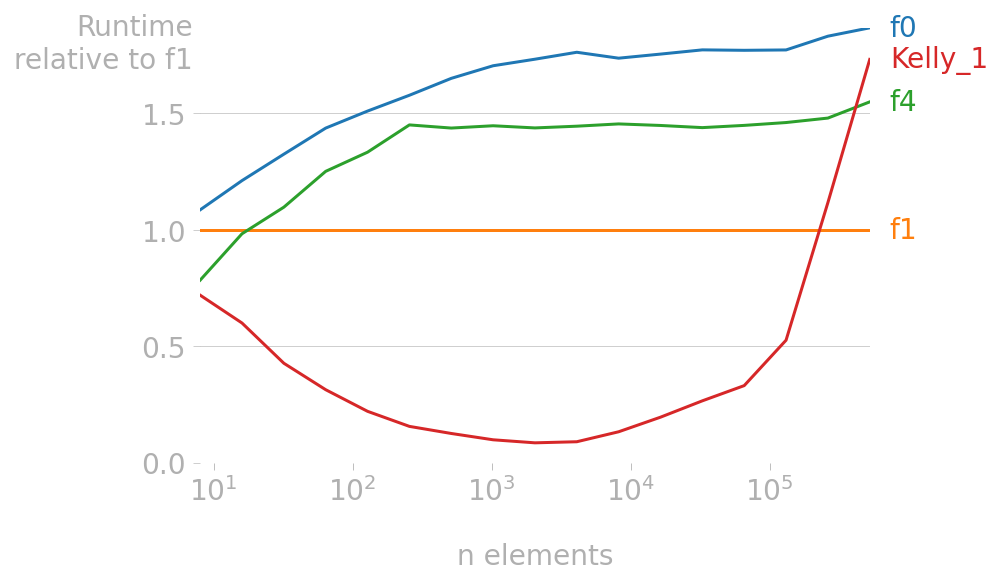
We see something very interesting about Kelly_1: even though it does some extra steps (copy the initial list, to protect the argument, sort the set to make it a sorted list), this absolutely obliterates all other solutions, up to about 100K elements. After that, the time ramps up significantly. I need to understand why.
Tested with Python 3.9.0.
CodePudding user response:
deleted_records = []
tokens = ['hi', 'what', 'is', 'there']
del_tokens = tokens []
indices_to_remove = [2,3]
for index in indices_to_remove:
deleted_records.append(tokens[index])
del_tokens[index]=''
del_tokens_real = []
for t in del_tokens:
if t!='':
del_tokens_real.append(t)
print(del_tokens_real)
print(deleted_records)
First replace records should delete with '' and then filter other records from it to get the output. Otherwise as the list size change during the delete issues can occur.
CodePudding user response:
Two solutions...
This one pops the values from back to front (relies on indices_to_remove being sorted):
def Kelly_1(tokens, indices_to_remove):
return [*map(tokens.pop, reversed(indices_to_remove))][::-1], tokens
This one gets the requested values and then copies the other values into a separate list using slices. Supports indices_to_remove being unsorted. If it's sorted, the sorted call can be removed.
def Kelly_2(tokens, indices_to_remove):
removed = [tokens[i] for i in indices_to_remove]
retained = []
start = 0
for i in sorted(indices_to_remove):
retained = tokens[start:i]
start = i 1
retained = tokens[start:]
return removed, retained
CodePudding user response:
Sort the indices list in descending order. If you remove the biggest index first, it can't possibly affect the index of elements earlier in the sequence.
deleted_records = []
tokens = ['hi', 'what', 'is', 'there']
indices_to_remove = [2,3]
for index in sorted(indices_to_remove, reverse=True):
deleted_tokens.append(tokens[index])
del tokens[index]