I have two lists to start with:
delta = ['1','5']
taxa = ['2','3','4']
My dataframe will look like :
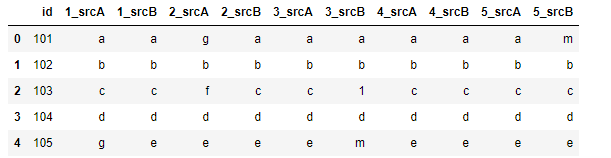
data = { 'id': [101,102,103,104,105],
'1_srcA': ['a', 'b','c', 'd', 'g'] ,
'1_srcB': ['a', 'b','c', 'd', 'e'] ,
'2_srcA': ['g', 'b','f', 'd', 'e'] ,
'2_srcB': ['a', 'b','c', 'd', 'e'] ,
'3_srcA': ['a', 'b','c', 'd', 'e'] ,
'3_srcB': ['a', 'b','1', 'd', 'm'] ,
'4_srcA': ['a', 'b','c', 'd', 'e'] ,
'4_srcB': ['a', 'b','c', 'd', 'e'] ,
'5_srcA': ['a', 'b','c', 'd', 'e'] ,
'5_srcB': ['m', 'b','c', 'd', 'e'] }
df = pd.DataFrame(data)
df
I have to do two types of checks on this dataframe. Say, Delta check and Taxa checks. For Delta checks, based on list delta = ['1','5'] I have to compare 1_srcA vs 1_srcB and 5_srcA vs 5_srcB since '1' is in 1_srcA ,1_srcB and '5' is in 5_srcA, 5_srcB . If the values differ, I have to populate 2. For tax checks (based on values from taxa list), it should be 1. If no difference, it is 0.
So, this comparison has to happen on all the rows. df is generated based on merge of two dataframes. so, there will be only two cols which has '1' in it, two cols which has '2' in it and so on.
Conditions I have to check:
- I need to check if columns containing values from delta list differs. If yes, I will populate 2.
- need to check if columns containing values from taxa list differs. If yes, I will populate 1.
- If condition 1 and condition 2 are satisfied, then populate 2.
- If none of the conditions satisfied, then 0.
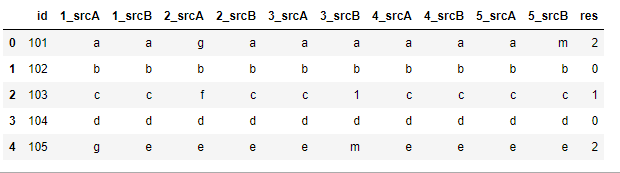
So, my output should look like:
The code I tried:
df_cols_ = df.columns.tolist()[1:]
conditions = []
res = {}
for i,col in enumerate(df_cols_):
if (i == 0) or (i%2 == 0) :
continue
var = 'cond_' str(i)
for del_col in delta:
if del_col in col:
var = var '_F'
break
print (var)
cond = f"df.iloc[:, {i}] != df.iloc[:, {i 1}]"
res[var] = cond
conditions.append(cond)
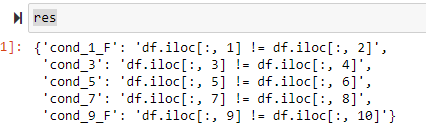
The res dict will look like the below. But how can i use the condition to populate?
Is the any optimal solution the resultant dataframe can be derived? Thanks.
CodePudding user response:
Create helper function for filter values by DataFrame.filter and compare them for not equal, then use np.logical_or.reduce for processing list of boolean masks to one mask and pass to numpy.select:
delta = ['1','5']
taxa = ['2','3','4']
def f(x):
df1 = df.filter(like=x)
return df1.iloc[:, 0].ne(df1.iloc[:, 1])
d = np.logical_or.reduce([f(x) for x in delta])
print (d)
[ True False False False True]
t = np.logical_or.reduce([f(x) for x in taxa])
print (t)
[ True False True False True]
df['res'] = np.select([d, t], [2, 1], default=0)
print (df)
id 1_srcA 1_srcB 2_srcA 2_srcB 3_srcA 3_srcB 4_srcA 4_srcB 5_srcA 5_srcB \
0 101 a a g a a a a a a m
1 102 b b b b b b b b b b
2 103 c c f c c 1 c c c c
3 104 d d d d d d d d d d
4 105 g e e e e m e e e e
res
0 2
1 0
2 1
3 0
4 2