I have DataFrame like this
d = {'id': [1, 2, 3, 4, 5, 6],
'y_true': [0, 0, 1, 1, 1, 0],
'y_pred': [0.23, 0.01, 0.19, 0.01, 0.3, 0.23]
}
df = pd.DataFrame(data=d)
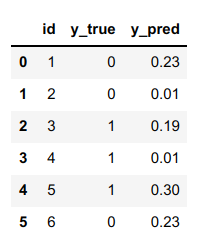
And I want to groupby y_pred and then groupby y_true for the same columns to find mean y_true for each row, corresponding to y_pred. So to speak
d1 = {'y_true': [0, 0.5, 1, 1],
'y_pred': [0.23, 0.01, 0.19, 0.3]
}
df1 = pd.DataFrame(data=d1)
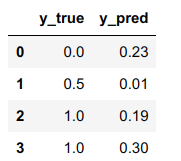
I know how groupby y_pred column, but I can only groupby y_true manually, row-by-row
CodePudding user response:
try:
df.groupby('y_pred')['y_true'].mean().reset_index()
# df.groupby("y_pred").apply(lambda x: x['y_true'].mean()).reset_index(name="y_true") #same
y_pred y_true
0 0.01 0.5
1 0.19 1.0
2 0.23 0.0
3 0.30 1.0
#or use numpy mean (maybe numpy has higher probability to be less wrong than panda mean)
import numpy as np
df.groupby('y_pred').agg({'y_true': np.mean}).reset_index()
#can combine both numpy mean and pandas mean
df.groupby('y_pred').agg(y_true_pd_mean=('y_true', 'mean'), y_true_np_mean=('y_true', np.mean)).reset_index()
y_pred y_true_pd_mean y_true_np_mean
0 0.01 0.5 0.5
1 0.19 1.0 1.0
2 0.23 0.0 0.0
3 0.30 1.0 1.0
#can also use mean from statistics module:
import statistics
df.groupby('y_pred').agg({'y_true': statistics.mean}).reset_index()