Let's imagine a web service X that has a single purpose - help to integrate two existing services (A and B) having different domain models. Some sort of adapter pattern.
There are cases when A wants to call B, and cases when B wants to call A.
How should endpoints of X be named to make clear for which direction each endpoint is meant?
For example, let's assume that the service A manages "apples". And the service B wants to get updates on "apples".
The adapter service X would have two endpoints:
PUT /apples- when A wants to push updated "apples" to BGET /apples- when B wants read "apples" from A (without awaiting a push from A)
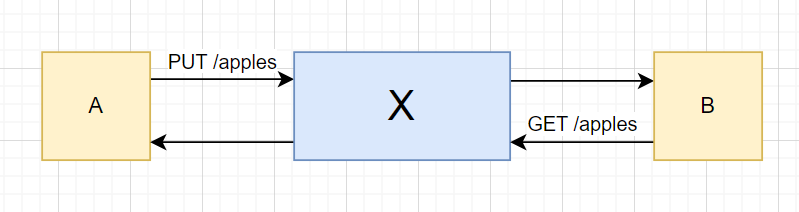
Such endpoint structure as above is quite misleading. The endpoints are quite different and use different domain models: PUT-endpoint awaits model of A, and GET-endpoint return model of B.
I would appreciate any advice on designing the API in such a case.
I don't like my own variant:
PUT /gateway-for-A/apples
GET /gateway-for-B/apples
CodePudding user response:
Not sure why you need to distinguish it in the path and why the domain or subdomain is not enough for it:
A: PUT x.example.com/apples -> X: PUT b.example.com/apples
B: GET x.example.com/apples -> X: GET a.example.com/apples
As of the model, you want to do PUSH-PULL in a system which is designed for REQ-REP. Let's translate the upper: pushApples(apples) and pullApples() -> apples if this is all they do, then PUT and GET are just fine with the /apples URI if you ask me. Maybe /apples/new is somewhat more expressive if you need only the updates, but I would rather use if-modified-since header instead and maybe push with if-unmodified-since.
Though I think you should describe what the two service does, not what you do with the apples, which appear to be a collection of database entities instead of a web resource, which is several layers above the database. Currently your URIs describe the communication, not the services. For example why is X necessary, why don't they call each other directly? If you can answer that question, then you will understand what X does with the apples and how to name its operations and how to design the URIs and methods which describe them.
CodePudding user response:
First things first: REST has no endpoints, but resources
Next, in terms of HTTP you should use the same URI for updating the state of a resource and retrieving updates done to it as caching, which basically uses the effective URI of a resource, will automatically invalidate any stored responses for an URI if a non-safe operation is performed on it and forward the request to the actual server. If you split concerns onto different URIs you basically bypass that cache management performed for you under the hood completely.
Note further, HTTP/0.9, HTTP/1.0 and HTTP/1.1 itself don't have a "push" option. It is a request-response protocol and as such if a client is interested in getting updates done to a resource it should poll the respective resource whenever it needs updates. If you need above-mentioned push though you basically need to switch to Web Sockets or the like. While HTTP/2 introduced server push functionality, this effectively just populates your local 2nd level cache preventing the client from effectively requesting the resource and instead using the previously received and cached one.
Such endpoint structure as above is quite misleading. The endpoints are quite different and use different domain models: PUT-endpoint awaits model of A, and GET-endpoint return model of B.
A resource shouldn't map your domain model 1:1. Usually in a REST architecture there can be way more resources than there are entities in your domain model. Just think of form-like resources that explain a client on how to request the creation or update of a resource or the like.
On the Web and therefore also in REST architectures the representation format exchanged should be based on well-defined media-types. These media types should define the syntax and semantics of elements that can be found within an exchanged document of that kind. The elements in particular provide the affordance that tell a client in particular what certain elements can be used for. I.e. a button wants to be pressed while a slider can be dragged left or right to change some numeric values or the like. You never have to frequent any external documentation once support for that media type is added to your client and/or server. A rule of thumb in regards to REST is to design the system as if you'd interact with a traditional Web page and then apply the same concepts you used for interacting with that Web page and translate it onto the REST application domain.
Client and server should furthermore use content-type negotiation to negotiate which representation format the server should generate for responses so that clients can process them. REST is all about indirections that ultimately allow a server to change its internals without affecting clients that behave well negatively. Staying interoperable whilst changing is an inherent design decision of REST. If that is not important to you, REST is probably overkill for your needs and you probably should use something more (Web-) RPC based.
In regards to you actual question, IMO a messaging queue could be a better fit to your problem than trying to force your design onto a REST architecture.
CodePudding user response:
In my view, it is fine, but can be improved:
PUT /gateway-for-A/apples
GET /gateway-for-B/apples
Because
- forward slashes are conventionally used to show the hierarchy between individual resources and collections:
/gateway-for-A/apples
What can be improved:
- it is better to use lowercase
- remove unnecessary words
So I would stick with the foloowing URI:
PUT /a/apples
GET /b/apples
Read more here about Restful API naming conventions