Hope I am asking this the right way - just confused with what's going on: I have my working script (below). I'm trying to take the URLs from a spreadsheet, rather than copy and paste them in - basically, creating urlsA from column N on the sheet connected.
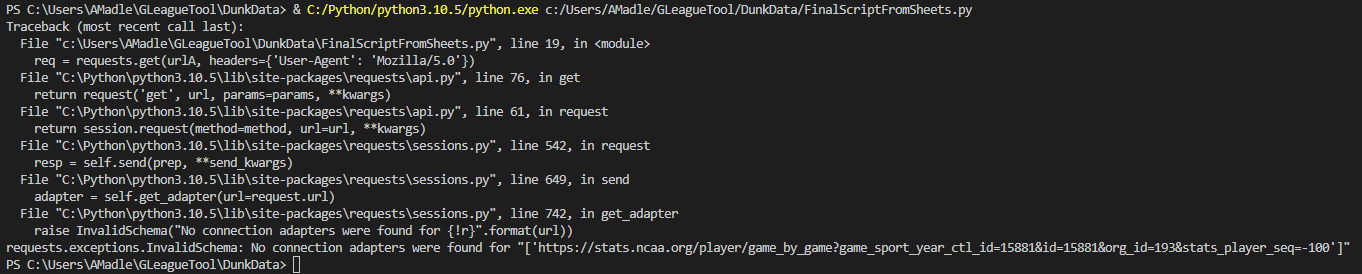
I've tested it out - I can print urlsA to terminal no problem, so I know the Sheet connection is working. I just can't seem to use them when I try to run the full script. I'm receiving this error:
Working code (before pulling links from Google Sheet):
from bs4 import BeautifulSoup
import requests
import time
import pandas as pd
import csv
profilesA = []
urlsA = ['https://stats.ncaa.org/player/game_by_game?game_sport_year_ctl_id=15881&id=15881&org_id=2&stats_player_seq=-100',
'https://stats.ncaa.org/player/game_by_game?game_sport_year_ctl_id=15881&id=15881&org_id=6&stats_player_seq=-100',
'https://stats.ncaa.org/player/game_by_game?game_sport_year_ctl_id=15881&id=15881&org_id=7&stats_player_seq=-100',
'https://stats.ncaa.org/player/game_by_game?game_sport_year_ctl_id=15881&id=15881&org_id=17&stats_player_seq=-100',
'https://stats.ncaa.org/player/game_by_game?game_sport_year_ctl_id=15881&id=15881&org_id=23&stats_player_seq=-100']
for urlA in urlsA:
req = requests.get(urlA, headers={'User-Agent': 'Mozilla/5.0'})
time.sleep(5)
soup = BeautifulSoup(req.text, 'html.parser')
for profileA in soup.select('.smtext > a[href^="/contests/"]'):
profileA = 'https://stats.ncaa.org' profileA.get('href')
profilesA.append(profileA)
profilesB = []
urlsB = profilesA
for urlB in urlsB:
req = requests.get(urlB, headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(req.text, 'html.parser')
for profileB in soup.select('a[href^="/game/play_by_play/"]'):
profileB = 'https://stats.ncaa.org' profileB.get('href')
profilesB.append(profileB)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
urls = profilesB
s = requests.Session()
s.headers.update(headers)
for url in urls:
gameId = url.split('/')[-1]
r = s.get(url)
dfs = pd.read_html(r.text)
for df in dfs:
if len(df.columns) > 2:
if df.iloc[0, 2] == 'Score':
df[4] = df[3]
df[[2, 3]] = df[2].str.split('-', expand=True)
df.to_csv('2022test.csv', mode='a', index=False)
Broken code: "No connection adapters were found" error:
from bs4 import BeautifulSoup
import requests
import time
import pandas as pd
import csv
from unittest import skip
import json
import gspread
gc = gspread.service_account(filename='creds.json')
sh = gc.open_by_key('1cEQlPB_ykJrucnbGgKhlKj49RdLNAzeO6fiO2gkQeNU')
wk = sh.worksheet("Team Select")
profilesA = []
ShUrls = wk.batch_get(('N3:N',))[0]
urlsA = ShUrls
for urlA in urlsA:
req = requests.get(urlA, headers={'User-Agent': 'Mozilla/5.0'})
time.sleep(5)
soup = BeautifulSoup(req.text, 'html.parser')
for profileA in soup.select('.smtext > a[href^="/contests/"]'):
profileA = 'https://stats.ncaa.org' profileA.get('href')
profilesA.append(profileA)
profilesB = []
urlsB = profilesA
for urlB in urlsB:
req = requests.get(urlB, headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(req.text, 'html.parser')
for profileB in soup.select('a[href^="/game/play_by_play/"]'):
profileB = 'https://stats.ncaa.org' profileB.get('href')
profilesB.append(profileB)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
urls = profilesB
s = requests.Session()
s.headers.update(headers)
for url in urls:
gameId = url.split('/')[-1]
r = s.get(url)
dfs = pd.read_html(r.text)
for df in dfs:
if len(df.columns) > 2:
if df.iloc[0, 2] == 'Score':
df[4] = df[3]
df[[2, 3]] = df[2].str.split('-', expand=True)
df.to_csv('2022test.csv', mode='a', index=False)
CodePudding user response:
I'd inspect this line:
ShUrls = wk.batch_get(('N3:N',))[0]
As you might be pulling a list of lists, hence, this line breaks
req = requests.get(urlA, headers={'User-Agent': 'Mozilla/5.0'})
with the No connection adapters were found error as a list is not a valid URL.
CodePudding user response:
Needed to flatten urlsA after seeing it was an array of arrays. Using this, then calling flatten fixed the issue:
def flatten(l):
fl = []
for sublist in l:
for item in sublist:
fl.append(item)
return fl