I'm trying to group a dataframe and sum each group and then sum the entire dataframe at the bottom. I have this working but I'm stumped with the grand total. I would also like to figure out how to have only one value in the host_count for each group.
import pandas as pd
# import numpy as np
data = {'host': ['1.1.1.1', '192.168.1.1', '192.168.1.1', '192.168.1.1', '172.16.1.2', '192.168.1.1', '172.16.1.2', '10.2.3.4', '10.0.0.1', '10.0.0.1'],
'url': ['capps.test.com', 'attilab-admin.test.com', 'emea-solutions-admin.test.com', 'ilab-admin.test.com', 'learning.test.com', 'mktextfw.test.com', 'sandbox.learning.test.com', 'mynetwork.test.com', 'www.letsdoit.com', 'www.mysite.com']}
df = pd.DataFrame(data)
df['host_count'] = df.groupby('host')['url'].transform('count')
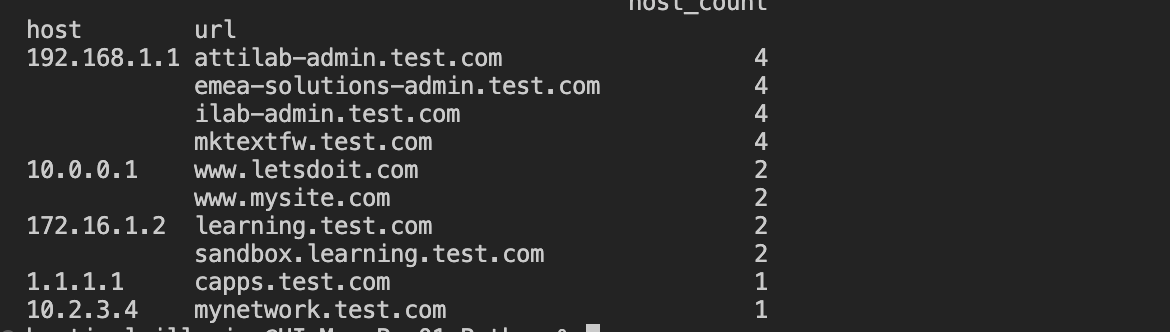
pivot1 = pd.pivot_table(df, index=['host', 'url'], columns=None, fill_value=0, dropna=True).sort_values(by='host_count', ascending=False)
print(pivot1)
CodePudding user response:
Use .loc to add a new row, which goes to the bottom of the frame by default. I think your problem can better be solved with groupby rather than pivot:
def summarize(group):
tmp = group.groupby("url").sum()
tmp.loc["All"] = tmp.sum()
return tmp
result = df.groupby("host").apply(summarize)
result.loc[("All", "All"), :] = result[result.index.get_level_values("url") != "All"].sum()
CodePudding user response:
Is this what you're looking for?
df.pivot_table(index='host', values='url', aggfunc='nunique', margins=True)
Output:
url
host
1.1.1.1 1
10.0.0.1 2
10.2.3.4 1
172.16.1.2 2
192.168.1.1 4
All 10
CodePudding user response:
I'm looking for output like this:
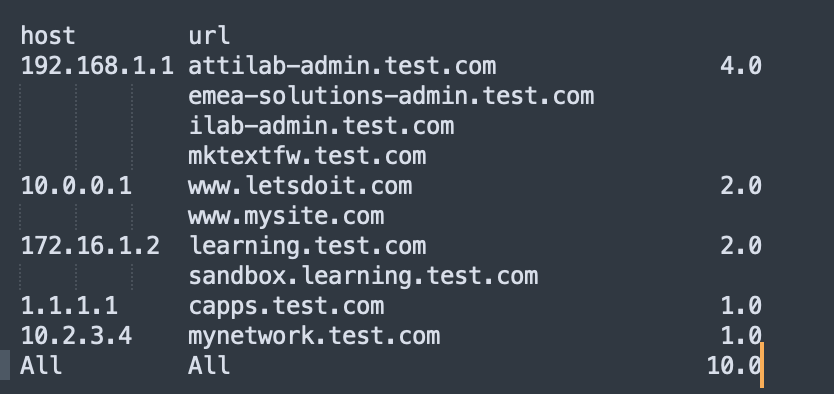
CodePudding user response:
This is getting close, but I would like to sum each group based on the "host" "url" group and then sum the total count.
import pandas as pd
data = {'host': ['1.1.1.1', '192.168.1.1', '192.168.1.1', '192.168.1.1', '172.16.1.2', '192.168.1.1', '172.16.1.2', '10.2.3.4', '10.0.0.1', '10.0.0.1'],
'url': ['capps.test.com', 'attilab-admin.test.com', 'emea-solutions-admin.test.com', 'ilab-admin.test.com', 'learning.test.com', 'mktextfw.test.com', 'sandbox.learning.test.com', 'mynetwork.test.com', 'www.letsdoit.com', 'www.mysite.com']}
df = pd.DataFrame(data)
df['host_count'] = df.groupby('host')['url'].transform('count')
pivot1 = df.pivot_table(index=['host', 'url'], values='host_count', aggfunc='nunique')
pivot1.loc[("All", "All"), :] = pivot1.sum()
print(pivot1)