I have a dataframe as shown below,
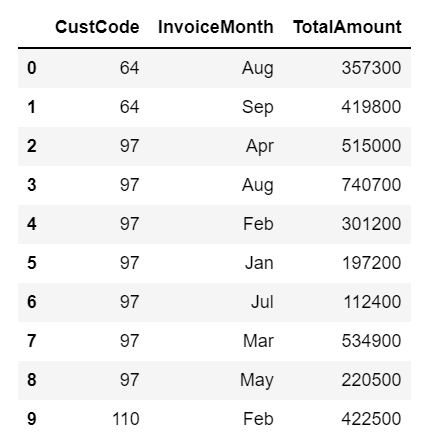
data_dict = {'CustCode': {0: 64, 1: 64, 2: 97, 3: 97, 4: 97, 5: 97, 6: 97, 7: 97, 8: 97, 9: 110}, 'InvoiceMonth': {0: 'Aug', 1: 'Sep', 2: 'Apr', 3: 'Aug', 4: 'Feb', 5: 'Jan', 6: 'Jul', 7: 'Mar', 8: 'May', 9: 'Feb'}, 'TotalAmount': {0: 357300, 1: 419800, 2: 515000, 3: 740700, 4: 301200, 5: 197200, 6: 112400, 7: 534900, 8: 220500, 9: 422500}}
How can I convert that into something like this(created manually few rows to show desired DataFrame),

Any help will be appreciated.
CodePudding user response:
You need to pivot your table, and since there are some missing months on your sample you also need to add them seperately:
import numpy as np
new_df = df.pivot(index='CustCode', columns='InvoiceMonth', values='TotalAmount')
months = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"]
new_df[[col for col in months if col not in new_df.columns]] = np.nan
new_df['Total'] = new_df.sum(axis=1)
new_df.reset_index(inplace=True)
CodePudding user response:
Try:
df = df.pivot(index="CustCode", columns="InvoiceMonth", values="TotalAmount")
months = [
"Jan",
"Feb",
"Mar",
"Apr",
"May",
"Jun",
"Jul",
"Aug",
"Sep",
"Oct",
"Nov",
"Dec",
]
df = df.reindex(months, axis=1)
df["Total"] = df.sum(axis=1)
df = df.fillna("").reset_index()
df.index.name, df.columns.name = None, None
print(df)
Prints:
CustCode Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Total
0 64 357300.0 419800.0 777100.0
1 97 197200.0 301200.0 534900.0 515000.0 220500.0 112400.0 740700.0 2621900.0
2 110 422500.0 422500.0
CodePudding user response:
Here is another proposition by using pandas.to_datetime to sort the columns without a dict :
out = (df.assign(month=pd.to_datetime(df['InvoiceMonth'], format='%b').dt.month)
.set_index('month').sort_index()
.reset_index(drop=True)
.pivot_table(index='CustCode', columns=('InvoiceMonth'), values='TotalAmount', sort=False)
.reset_index()
.rename_axis(None,axis=1)
)
out['Total'] = out.sum(axis=1)
To separate thousands with comma, use :
pd.options.display.float_format = '{:,}'.format
# Output :
print(out)
CustCode Jan Feb Mar Apr May Jul Aug Sep Total
0 97 197,200.0 301,200.0 534,900.0 515,000.0 220,500.0 112,400.0 740,700.0 NaN 2,621,997.0
1 110 NaN 422,500.0 NaN NaN NaN NaN NaN NaN 422,610.0
2 64 NaN NaN NaN NaN NaN NaN 357,300.0 419,800.0 777,164.0