I have the following data:
import pandas as pd
data = {'Customer_ID': [1, 1, 1, 2, 2, 3, 4, 4, 5, 5, 5, 5, 6, 6],
'Loan': [200, 250, 300, 400, 300, 500, 150, 150, 400, 250, 150, 300, 200, 200],
'CustomerGender': ['M', 'M', 'M', 'F', 'F', 'M', 'M', 'M', 'F', 'F', 'F', 'F', 'F', 'F'],
'Agent_ID': [306, 306, 306, 306, 306, 307, 308, 308, 309, 309, 309, 309, 309, 309],
'AgentGender': ['F', 'F', 'F', 'M', 'M','M', 'M', 'M', 'F', 'F', 'F', 'F', 'F', 'F'],
'settlement_value': [23.5, 30.99, 306, 86, 50, 307.35, 1200.54, 25, 48.88, 400, 2100.10, 30, 1309.10, 500.50]}
I would like to aggregate them by Customer_ID. Background info: There are six customers who took out loans multiple times offered by Agents (denoted by Agent_ID). Agents serve multiple customers. For example Agent with ID 306 provided loans to Customer 1 and 2. Similarly, Agent with ID 309 provided loans to Customer 5 and 6. I would like to aggregate the amount of loans each customer took and get something like in the table below. It is important I see the gender of the customer and agent after aggregation.
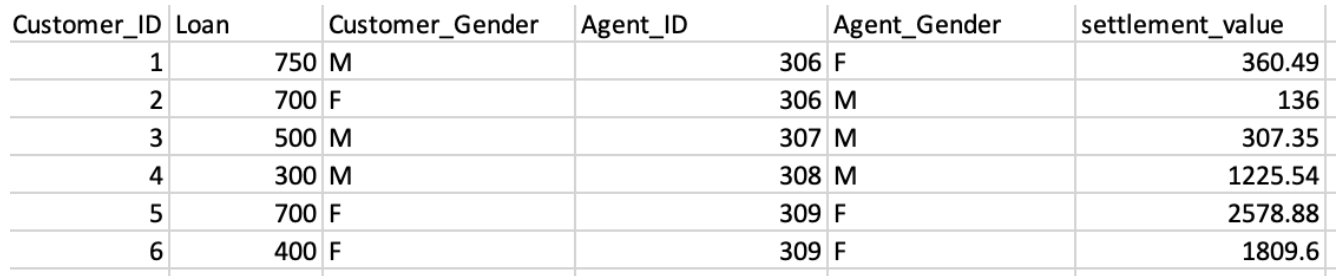
I tried the following code:
# declare the two gender columns categorical.
data['AgentGender']=data['AgentGender'].astype('category')
data['CustomerGender']=data['CustomerGender'].astype('category')
# transform to dataframe
data = pd.DataFrame(data)
# aggregate the data by Customer_ID to see the total amount of loan each customer took. The two gender variables do not appear when running this code.
data = data.groupby(data.Customer_ID, observed=True).sum().reset_index()
data
# the following code aggregates the data and shows the two gender variables, only if I don't include the 'settlement_value'.
data1 = data.groupby(['Customer_ID','CustomerGender','Agent_ID', 'AgentGender'], observed=True)['Loan'].sum().reset_index()
data1
# if I include 'settlement_value', aggregation does not work at all:
data2 = data.groupby(['Customer_ID','CustomerGender','Agent_ID', 'AgentGender', 'settlement_value'], observed=True)['Loan'].sum().reset_index()
data2
Can you please help me fix this code? Many thanks.
CodePudding user response:
data.groupby(['Customer_ID','CustomerGender','Agent_ID','AgentGender'], observed=True).sum().reset_index()
CodePudding user response:
Is this something you are looking for?
f = {'Loan': 'sum', 'CustomerGender': 'first', 'Agent_ID': 'first', 'AgentGender': 'first', 'settlement_value': 'sum'}
df.groupby(['Customer_ID'], as_index=False).agg(f)
returns
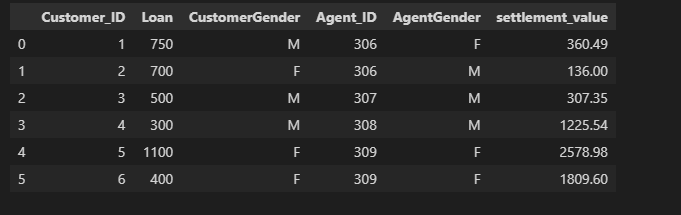
CodePudding user response:
df.groupby(['Customer_ID', 'CustomerGender', 'Agent_ID', 'AgentGender'], observed=True).agg({'Loan': 'sum', 'settlement_value': 'sum'}).reset_index()
Customer_ID CustomerGender Agent_ID AgentGender Loan settlement_value
0 1 M 306 F 750 360.49
1 2 F 306 M 700 136.00
2 3 M 307 M 500 307.35
3 4 M 308 M 300 1225.54
4 5 F 309 F 1100 2578.98
5 6 F 309 F 400 1809.60