Context: I have 2 dataframes one with weekly sums for a given month/year, etc and another dataframe that takes the sum of that given month/ year. This is done to get the % values.
Lets say we have dataframe 1 with the total counts:
pd.DataFrame({'Col1':['A','A','A'],
'Col2':['B1','B2','B3'],'Total_Counts':[10,20,30]})
Col1 Col2 Total_Counts
0 A B1 10
1 A B2 20
2 A B3 30
And dataframe 2 with the weekly counts:
pd.DataFrame({'Col1':['A','A','A','A','A','A','A','A','A'],
'Col2':['B1','B2','B3','B1','B2','B3','B1','B2','B3'],
'Weekly_Counts':[1,4,6,10,4,6,12,12,6]})
Col1 Col2 Weekly_Counts
0 A B1 1
1 A B2 4
2 A B3 6
3 A B1 10
4 A B2 4
5 A B3 6
6 A B1 12
7 A B2 12
8 A B3 6
How can I divide element by element matching col1 and col2?
I was trying this:
result= (weekly_dataframe.merge(total_dataframe,
left_on=['Col1','Col2'],
right_on=['Col1','Col2'],how='left')
.assign(new=lambda x:round(x['Weekly_Counts'].div(x['Total_Counts'])*100,2))
.reindex(columns=[*weekly_dataframe.columns] ['Percentage']))
But the new column percentage keeps giving NaN
Desired output:
So when I just do weekly_dataframe.merge(total_dataframe,left_on=['Col1','Col2'], right_on=['Col1','Col2'],how='left') I get to this image with Total_Counts_x and Total_Counts_y

When I change the code to this (note I added Total_Count_x and y):
result= (weekly_dataframe.merge(total_dataframe,
left_on=['Col1','Col2'],
right_on=['Col1','Col2'],how='left')
.assign(new=lambda x:round(x['Total_Counts_x'].div(x['Total_Counts_y'])*100,2))
.reindex(columns=[*weekly_dataframe.columns] ['Percentage']))
I get this:
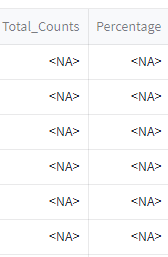
How could I fix this issue?
Thank you
CodePudding user response:
Since you're using pandas.DataFrame.assign, you don't need to reindex the cols to rename the %.
Try this :
result= (
weekly_dataframe.merge(total_dataframe,on=['Col1','Col2'],how='left')
.assign(Percentage=lambda x:round(x['Weekly_Counts'].div(x['Total_Counts'])*100,2))
)
# Output :
print(result)
Col1 Col2 Weekly_Counts Total_Counts Percentage
0 A B1 1 10 10.0
1 A B2 4 20 20.0
2 A B3 6 30 20.0
3 A B1 10 10 100.0
4 A B2 4 20 20.0
5 A B3 6 30 20.0
6 A B1 12 10 120.0
7 A B2 12 20 60.0
8 A B3 6 30 20.0
CodePudding user response:
IIUC, is that what you're looking for? map will have a better performance over the merge
# create a dictionary of the col2 and total-counts from DF
d=dict(df[['Col2', 'Total_Counts']].values)
# map the total count from df using dict
df2['Total_counts'] = df2['Col2'].map(d)
#calculate
df2['percentage']=(df2['Weekly_Counts']/df2['Total_counts'] )*100
df2
Col1 Col2 Weekly_Counts Total_counts percentage
0 A B1 1 10 10.0
1 A B2 4 20 20.0
2 A B3 6 30 20.0
3 A B1 10 10 100.0
4 A B2 4 20 20.0
5 A B3 6 30 20.0
6 A B1 12 10 120.0
7 A B2 12 20 60.0
8 A B3 6 30 20.0