For context I'm a SAS programmer in clinical trials but I have this spec for variable ADTC.
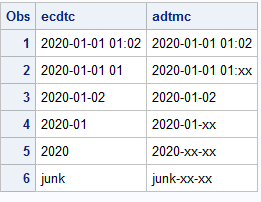
If EC.ECDTC contains a full datetime, set ADTMC to the value of EC.ECDTC in "YYYY-MM-DD hh:mm" format. If EC.ECDTC contains a full or partial date but no time part then set ADTMC to the date part of EC.ECDTC in "YYYY-MM-DD" format. In both cases, replace any missing elements of the format with "XX", for example "2022-01-01 16:XX" or "2022-01-XX"
So currently I'm using this piece of code which is partially fine but not ideal
check=count(ecdtc,'-');
if check = 0 and ~missing(ecdtc) then adtc = cats(ecdtc,"-XX-XX");
else if check = 1 then adtc = cats(ecdtc,"-XX");
else if check = 2 then adtc = ecdtc;
Is there a way I could use perl-regular expressions to have like a template of the outline of the date/datetime and have it search through the values for that column and if they don't match to add -XX if missing day or -XX-XX if missing day and month etc. I was thinking of utilising prxchange but how do you incorporate the template so it knows to add -XX in the correct position where applicable.
CodePudding user response:
Honestly, I wouldn't; regex are not faster for the most part than just straight-up checking with normal code, for simple things like this. If you have time pressure, or thousands or millions of rows... not a good idea, just use scan.
But that said, it's certainly possible, and somewhat interesting. We'll use PRXPOSN, which lets us iterate through the capture buffers, and "capture" each bit. This might need some tweaking, and you might need to capture/not capture the hyphens for example, but for my data this works - if your data is different, the regex will be different (and next time, post sample data!).
data have;
length ecdtc $16;
infile datalines truncover;
input @1 ecdtc $16.;
datalines;
2020-01-01 01:02
2020-01-02
2020-01
2020
junk
;;;;
run;
data want;
set have;
length adtmc $16;
array vals[3] $;
vals[1]='XXXX';
vals[2]='-XX';
vals[3]='-XX';
_rx = prxparse('/(\d{4})(-\d{2})?(-\d{2})?( \d{2}:\d{2})?/ios');
_rc = prxmatch(_rx,ecdtc); *this does the matching. Probably should check for value of _rc to make sure it matched before continuing.;
do _i = 1 to 4; *now iterate through the four capture buffers;
_rt = prxposn(_rx,_i,ecdtc);
if _i le 3 then vals[_i] = coalescec(_rt,vals[_i]);
else timepart = _rt; *we do the timepart outside the array since it needs to be catted with a space while the others do not, easier this way;
end;
adtmc = cats(of vals[*]); *cat them together now - if you do not capture the hyphen then use catx ('-',of vals[*]) instead;
if timepart ne ' ' then adtmc = catx(' ',adtmc,timepart); *and append the timepart after.;
run;
CodePudding user response:
SUBSTR on the left.
data want2;
set have;
length adtmc $16;
if length(ecdtc) le 10 then adtmc = 'xxxx-xx-xx';
else adtmc = 'xxxx-xx-xx xx:xx';
substr(adtmc,1,length(ecdtc))=ecdtc;
run;