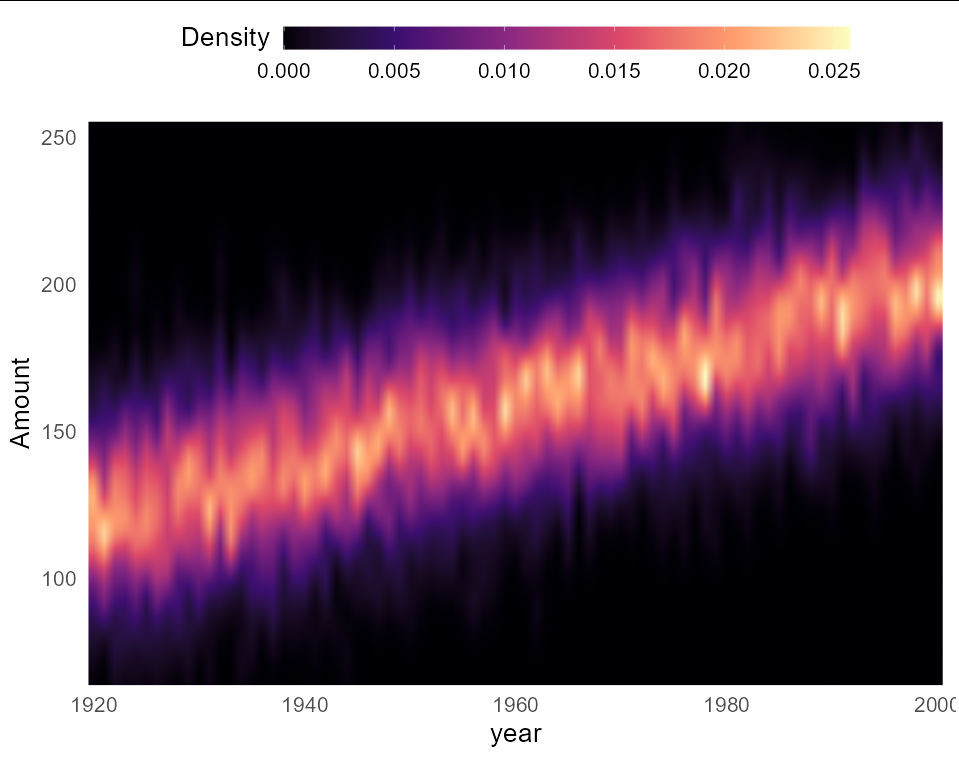
I measured the number of occurrences of exclamation marks in the abstract and title of papers per year. Now, I want to show the distribution of this number for each individual year using a kernel density estimation. I want to plot my data in a way that I found in another publication (Plavén-Sigray et al. eLife 2017, 
Do you have any idea how I could achieve this using R? I would be glad if you could provide a package. I added some toy data along with what I tested so far.
library(ggplot2)
set.seed(176)
df = data.frame(
id = seq(1:2000),
amount = sample(0:3, 2000, replace = TRUE),
year = sample(1990:2010, 2000, replace = T)
)
ggplot(df, aes(x = year, y = amount) )
geom_density_2d()
geom_density_2d_filled()
geom_density_2d(colour = "black")
I get the following result which is not really what I want:
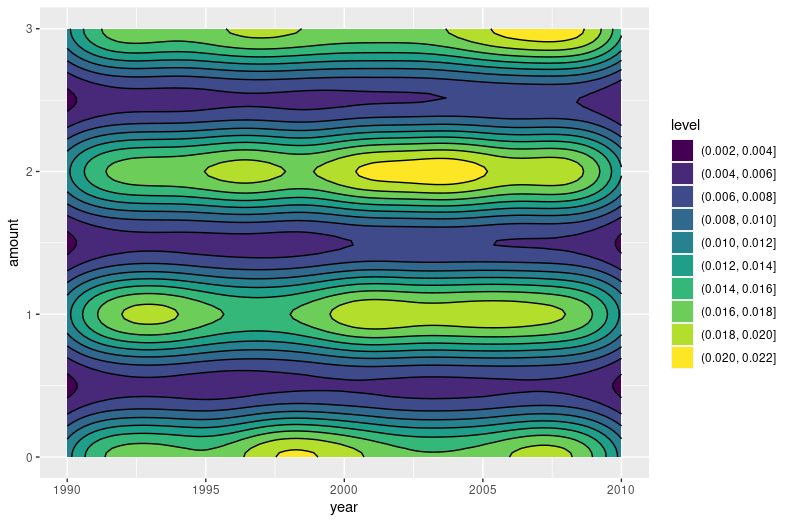
Any help would be appreciated. Thank you in advance!
CodePudding user response:
You can get a plot like this in ggplot directly without additional packages. Here's a full reprex:
set.seed(1)
df <- data.frame(year = rep(1920:2000, each = 100),
amount = rnorm(8100, rep(120:200, each = 100), 20))
library(tidyverse)
df %>%
group_by(year) %>%
summarize(Amount = density(amount, from = min(df$amount),
to = max(df$amount))$x,
Density = density(amount, from = min(df$amount),
to = max(df$amount))$y) %>%
ggplot(aes(year, Amount, fill = Density))
geom_raster(interpolate = TRUE)
scale_fill_viridis_c(option = "magma")
theme_minimal(base_size = 20)
coord_cartesian(expand = 0)
theme(legend.position = "top",
legend.key.width = unit(3, "cm"),
legend.title = element_text(vjust = 1))