In writing a grammar/parser for a regex, I'm wondering why the following constructions are both syntactically and semantically valid in the regex syntax (at least as far as I can understand it)?
- Repetitions of a character class, such as:
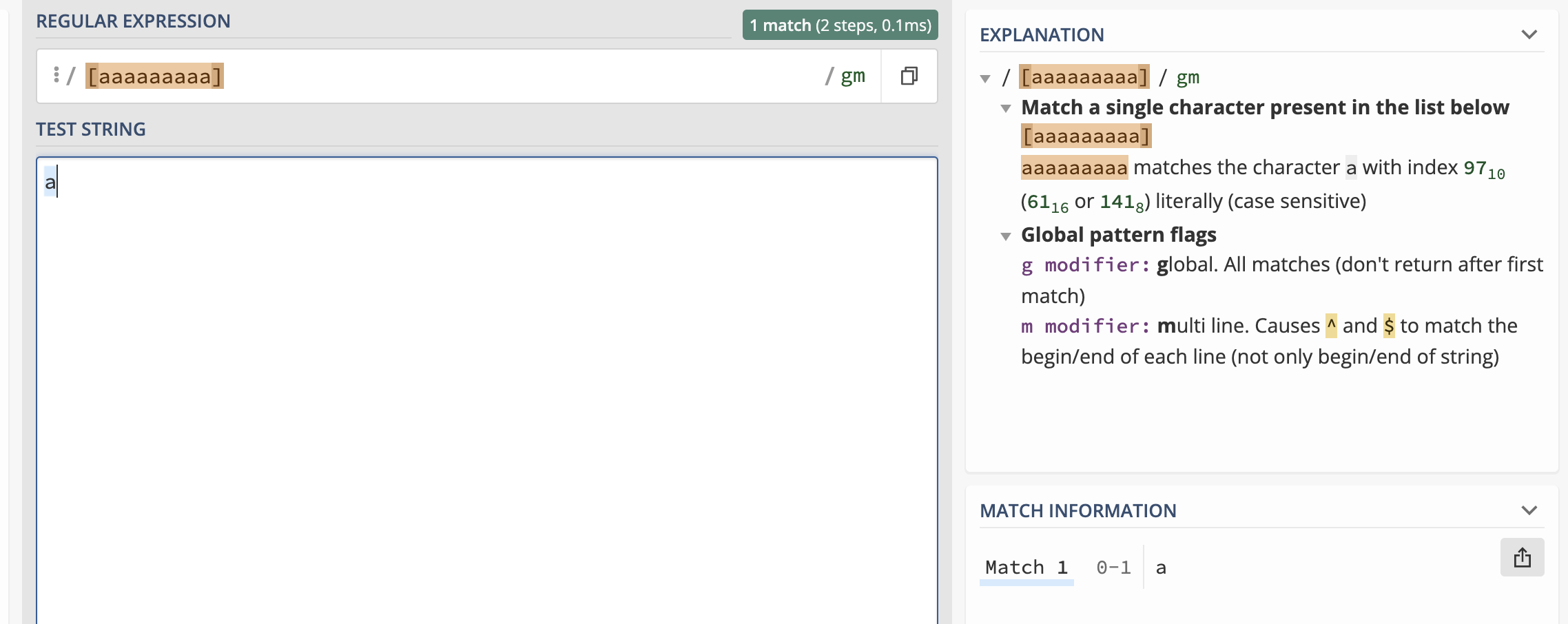
- Repetitions of a zero-width assertion, such as:
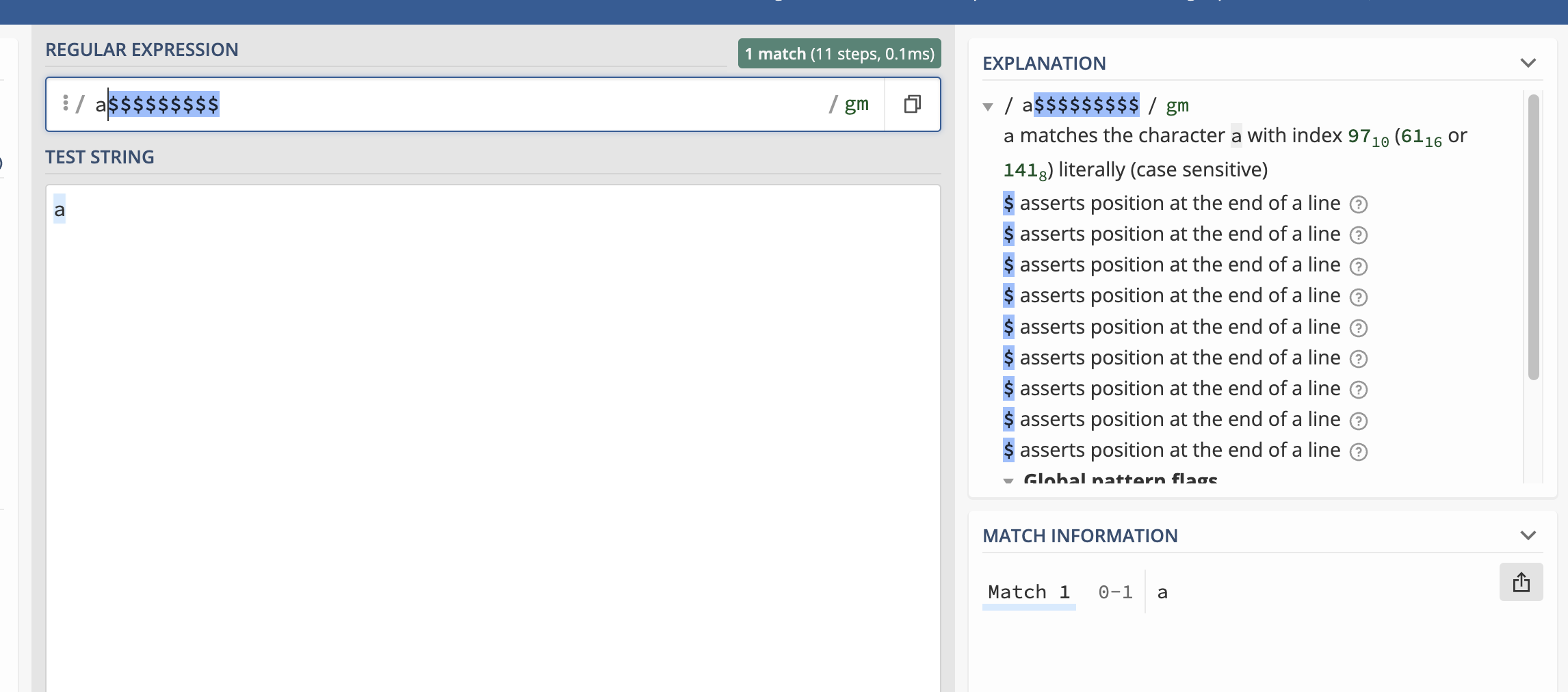
- Assertions at a bogus position, such as:
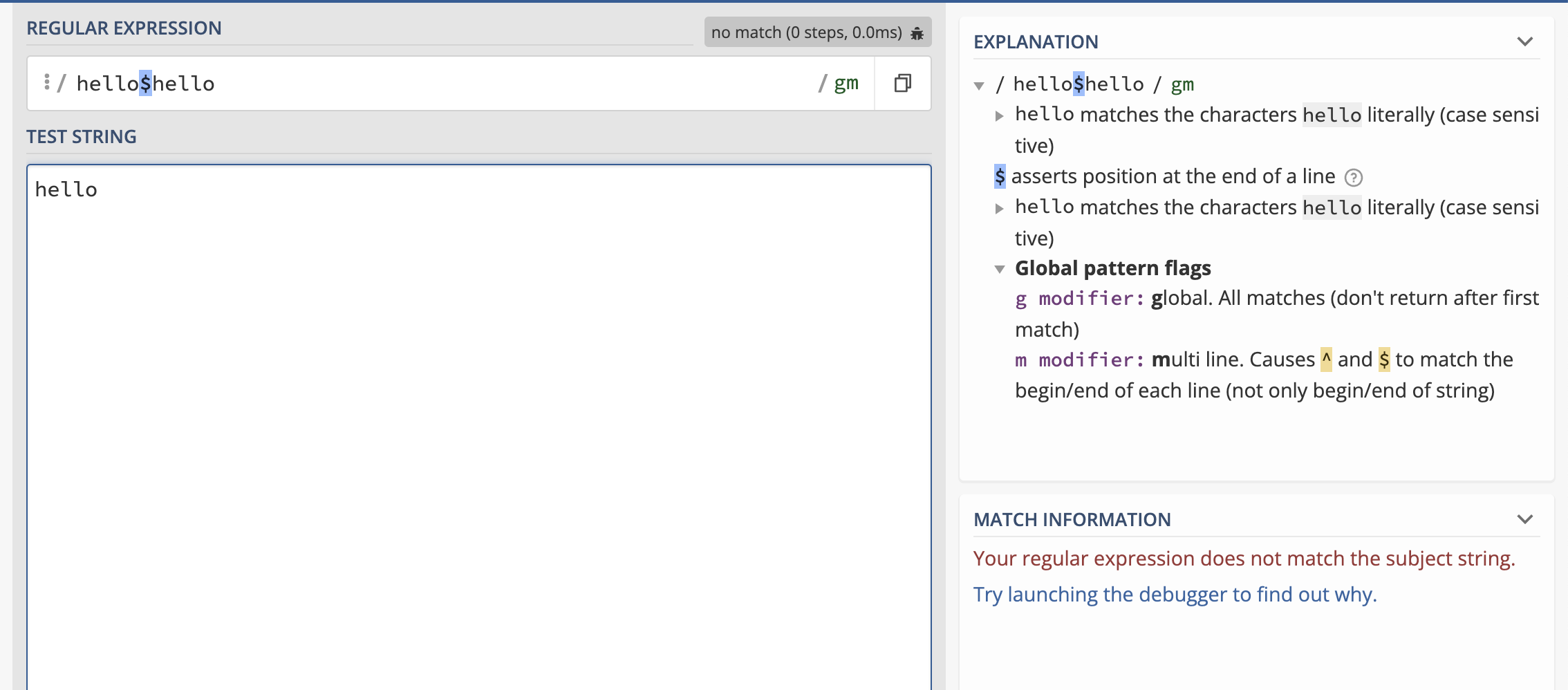
To me, this sort of seems like having a syntax that would allow having a construction like SELECT SELECT SELECT SELECT SELECT col FROM tbl. In other words, why isn't the regex syntax defined as more strict than it is in practice?
CodePudding user response:
To start with, that's not a very good analogy. Your statement with multiple SELECT keywords is not, as far as I know, part of the SQL grammar, so it's simply ungrammatical. Repeated elements in a character class are more like the SQL construct:
SELECT * FROM table WHERE Value IN (1, 2, 3, 2, 3, 2, 3)
I think most (if not all) SQL processors would allow that. You could argue that it would be nice if a warning message were issued, but the usual SQL interface (where a query is sent from client to server and a result returned) does not leave space for a warning.
It's certainly the case that repeated characters in a character class are often an indication that the regular expression was written by a novice with only a fuzzy idea of what a character class is. If you hang out in SO's flex-lexer long enough, you'll see how often students write regular expressions like [a-z|A-Z|0-9], or even [begin|end]. If flex detected duplicate characters in character classes, those mistakes would receive warnings, which might or might not be useful to the student coder. (Reading and understanding warning messages is not, apparently, an innate skill.) But it needs to be asked, Who is the target audience for a tool like Flex, and I think the answer is not "impatient beginners who won't read documentation". Certainly, a non-novice programmer might also make that kind of mistake, usually as a result of a typo, but it's not common and it will probably easily be detected during debugging.
If you've already started to work on a parser for regular expressions, you should already know why these rules are not usually a feature of regular expression libraries. Every rule you place on a syntax must be:
- precisely defined,
- documented,
- implemented,
- acted upon appropriately (which may mean complicating the interface in order to allow for warnings).
- and all of that needs to be thoroughly tested. That's a lot of work to prevent something which is not even technically an error.
Moreover, catching those errors (if they are errors) will probably make the "grammar" for the regular expressions context-sensitive. (In other words, you can't write a context-free grammar which forbids duplication inside a character class.)
Moreover, practically all of those expressions might show up in the wild, typically in the case that the regular expression was programmatically generated. For example, suppose you have a set of words, and you want to write a regular expression which will match any sequence of characters not in any of the words. The simple solution is [^firstsecondthirdwordandtherest] . Of course, you could have gone to the trouble of deduping the individual letters in the words, -- a simple task in some programming languages, but more complicated in others -- but should it be necessary?
With respect to your other two examples, with repeated and non-terminal $, there are actual regex libraries in which those interpreted in some different way. Many older regex libraries (including (f)lex) only treat $ as a zero-length end-of-string assertion if it appears at the very end of the regex; such libraries would treat all of those $s other than the last one in a$$$$$$$$ as matching a literal $. Others treat $ as an end-of-line assertion, rather than an end-of-string assertion. But I don't know of any which treat those as errors.
There's a pretty good argument that a didactic tool, such as regex101, might usefully issue warnings for doubtful regular expressions, a task usually called "linting". But for a production regex library, there is little to be gained, and a lot of pain.