I am unable to drop the index column which is normally given by the python on its own. I melted a data frame and for further processing, I need to drop the index column and I am unable to do that.
Attached is the data frame which is uploaded in df:
{'Key': {0: 65162552161356, 1: 65162552635756, 2: 65162552843456, 3: 65162552842856, 4: 65162552736856}, '2021-04-01': {0: 31, 1: 0, 2: 281, 3: 207, 4: 55}, '2021-05-01': {0: 25, 1: 0, 2: 72, 3: 104, 4: 6}, '2021-06-01': {0: 16, 1: 0, 2: 108, 3: 32, 4: 14}, '2021-07-01': {0: 8, 1: 0, 2: 107, 3: 78, 4: 10}, '2021-08-01': {0: 21, 1: 0, 2: 80, 3: 40, 4: 9}, '2021-09-01': {0: 24, 1: 0, 2: 40, 3: 73, 4: 3}, '2021-10-01': {0: 13, 1: 0, 2: 36, 3: 79, 4: 11}, '2021-11-01': {0: 59, 1: 0, 2: 65, 3: 139, 4: 14}, '2021-12-01': {0: 51, 1: 0, 2: 41, 3: 87, 4: 10}, '2022-01-01': {0: 2, 1: 0, 2: 43, 3: 47, 4: 6}, '2022-02-01': {0: 0, 1: 0, 2: 0, 3: 63, 4: 3}, '2022-03-01': {0: 0, 1: 0, 2: 16, 3: 76, 4: 18}, '2022-04-01': {0: 0, 1: 0, 2: 37, 3: 32, 4: 8}, '2022-05-01': {0: 0, 1: 0, 2: 106, 3: 96, 4: 40}, '2022-06-01': {0: 0, 1: 0, 2: 101, 3: 75, 4: 16}, '2022-07-01': {0: 0, 1: 0, 2: 60, 3: 46, 4: 14}, '2022-08-01': {0: 0, 1: 0, 2: 73, 3: 91, 4: 13}, '2022-09-01': {0: 0, 1: 0, 2: 19, 3: 17, 4: 2}
Can someone help me out and let me know how to make the changes.
df = pd.read_excel ('C:/X/X/X/Demand_Data_Used.xlsx')
df['Key'] = df['Key'].astype(str)
df = pd.melt(df,id_vars='Key',value_vars=list(df.columns[1:]),var_name ='ds')
df.columns = df.columns.str.replace('Key', 'unique_id')
df.columns = df.columns.str.replace('value', 'y')
df["ds"] = pd.to_datetime(df["ds"],format='%Y-%m-%d')
df=df[["ds","unique_id","y"]]
df
The df data frame looks like this after the completion of this operation:
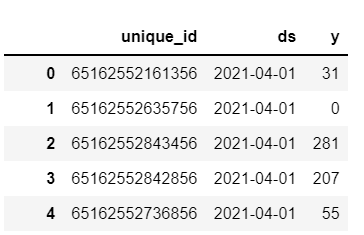
I would like it to look like this:
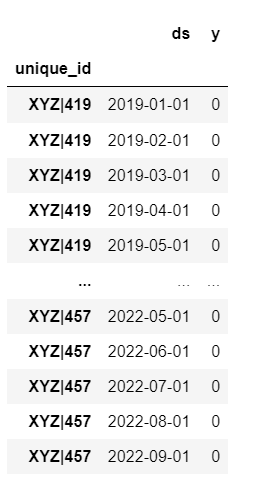
I know the doesnt contain the same values, I was just trying to show the expectation. Can someone help me in figure out the correct way to drop the index column?
CodePudding user response:
It looks like you don't actually want to drop the index column, but instead assign another column as the index. You can do this very easily with this assignment:
df.index = df["unique_id"]
Now if you want to drop the column afterwards (the value would now show up twice essentially), you can do this as well:
df = df.drop("unique_id", axis=1)