I have 2 tables viz. Table A and Table B Both tables have a common pk values. I am trying to find which value is missing in each table by achieving the expected result set.
I tried doing a between 2 queries by using a left join in 1st query and right join in 2nd query, but I couldn't achieve the expected result.
Any help would be appreciated.
Table A
|pk | values |
|---|----------|
|1 | Value A |
|1 | Value B |
|1 | Value C |
|2 | Value D |
|2 | Value E |
|2 | Value F |
|3 | Value G |
|3 | Value H |
|3 | Value I |
|4 | Value Z |
Table B
| pk | values |
|----|----------|
| 1 | Value A |
| 2 | Value D |
| 2 | Value E |
| 2 | Value F |
| 2 | Value J |
| 3 | Value G |
| 3 | Value K |
| 4 | Value Z |
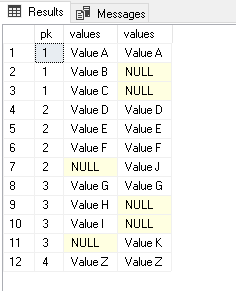
Expected Result
| pk | a.value | b.value |
|--- |----------|---------|
| 1 | Value A | Value A |
| 1 | Value B | *NULL* |
| 1 | Value C | *NULL* |
| 2 | Value D | Value D |
| 2 | Value E | Value E |
| 2 | Value F | Value F |
| 2 | *NULL* | Value J |
| 3 | Value G | Value G |
| 3 | Value H | *NULL* |
| 3 | Value I | *NULL* |
| 3 | NULL | Value K |
| 4 | Value Z | Value Z |
CodePudding user response:
Here is much simpler version by using FULL OUTER JOIN.
SQL
DECLARE @tableA TABLE (pk int, [values] varchar(50));
DECLARE @tableB TABLE (pk int, [values] varchar(50));
INSERT INTO @tableA (pk, [values]) VALUES
(1, 'Value A'),
(1, 'Value B'),
(1, 'Value C'),
(2, 'Value D'),
(2, 'Value E'),
(2, 'Value F'),
(3, 'Value G'),
(3, 'Value H'),
(3, 'Value I'),
(4, 'Value Z');
INSERT INTO @tableB (pk, [values]) VALUES
(1, 'Value A'),
(2, 'Value D'),
(2, 'Value E'),
(2, 'Value F'),
(2, 'Value J'),
(3, 'Value G'),
(3, 'Value K'),
(4, 'Value Z');
SELECT COALESCE(a.pk, b.pk) AS pk , a.[values], b.[values]
FROM @tableA AS a FULL OUTER JOIN
@tableB AS b ON b.pk = a.pk AND b.[values] = a.[values]
ORDER BY COALESCE(a.pk, b.pk);
Output
| pk | values | values |
|---|---|---|
| 1 | Value A | Value A |
| 1 | Value B | NULL |
| 1 | Value C | NULL |
| 2 | Value D | Value D |
| 2 | Value E | Value E |
| 2 | Value F | Value F |
| 2 | NULL | Value J |
| 3 | NULL | Value K |
| 3 | Value G | Value G |
| 3 | Value H | NULL |
| 3 | Value I | NULL |
| 4 | Value Z | Value Z |
CodePudding user response:
This is ugly and I would love some feedback on solution but it does produce expected output.
First some setup:
create table #tableA
(
pk int,
[values] varchar(50)
);
create table #tableB
(
pk int,
[values] varchar(50)
)
insert into #tableA
(pk, [values])
values
(1, 'Value A'),
(1, 'Value B'),
(1, 'Value C'),
(2, 'Value D'),
(2, 'Value E'),
(2, 'Value F'),
(3, 'Value G'),
(3, 'Value H'),
(3, 'Value I'),
(4, 'Value Z')
insert into #tableB
(pk, [values])
values
(1, 'Value A'),
(2, 'Value D'),
(2, 'Value E'),
(2, 'Value F'),
(2, 'Value J'),
(3, 'Value G'),
(3, 'Value K'),
(4, 'Value Z')
Then to reproduce expected results try this:
with cte as (
select distinct pk, [values] from #tableA
union
select distinct pk, [values] from #tableB
)
select c.pk, a.[values], b.[values] from (select pk, [values] from cte) c
left join #tableA a on a.[values] = c.[values]
left join #tableB b on b.[values] = c.[values]