I know spark use lazy operation. My question is that when I read the csv file as a spark dataframe and I do one transformation like below, what happened to the data in memory(RAM) after action operation.
df = spark.read.csv('example.csv')
df1 = df.withColumn("Y", df["X"])
df1.show()
After show operation, what happened to any intermediate results (data) in memory? does it remove from the memory? in other words If I runt df1.show() for the second time, does the spark read 'example.csv' again?
CodePudding user response:
I think some of these concepts may be explained well with an illustrative example:
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
spark = SparkSession\
.builder\
.appName("test")\
.getOrCreate()
file_name = './test.csv'
with open(file_name, 'w') as fp:
fp.write('foo, bar')
fp.write('\na, 1')
fp.write('\nb, 2')
df = spark.read.csv(file_name, header=True)
df = df.withColumn('baz', F.lit('test'))
df.show()
with open(file_name, 'a') as fp:
fp.write('\nc, 3')
df.show()
The output is:
--- ---- ----
|foo| bar| baz|
--- ---- ----
| a| 1|test|
| b| 2|test|
--- ---- ----
--- ---- ----
|foo| bar| baz|
--- ---- ----
| a| 1|test|
| b| 2|test|
--- ---- ----
Indicating the data is not re-read from the file - if it was, we would have the new row ((c, 3)) which was written.
For an explanation, if you navigate to the Spark UI (localhost:4040 while running locally) before calling df.show(), you will notice there is a job listed for reading the file, along with a corresponding DAG.

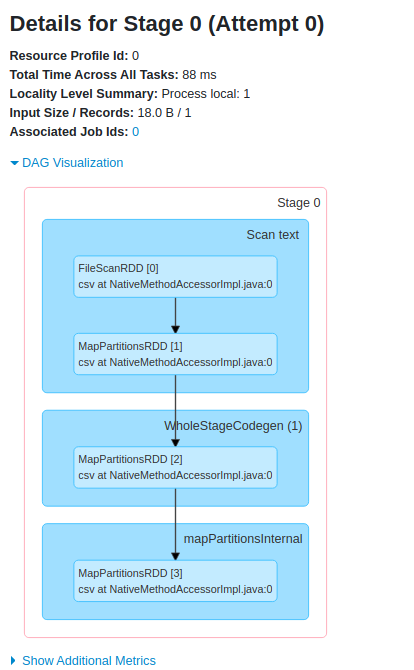
This indicates the dataframe being read into memory is an action (as in, not lazily evaluated), and the file won't be re-read unless explicitly told to with another call to spark.read.csv.
However, subsequent calculations performed after reading the dataframe into memory are not cached unless explicitly told to, using df.cache(). For example, if we were to add the following to the previous snippet:
df.filter(F.col('foo') == 'a').count()
df.filter(F.col('foo') == 'a').show()
The computations for performing the same filter will be repeated, whereas if we add a cache call:
df.filter(F.col('foo') == 'a').cache()
df.filter(F.col('foo') == 'a').count()
df.filter(F.col('foo') == 'a').show()
The computations will be saved in memory. This can be seen by the difference in plans (see images below) - specifically, in the cache case, notice there is an InMemoryTableScan step.
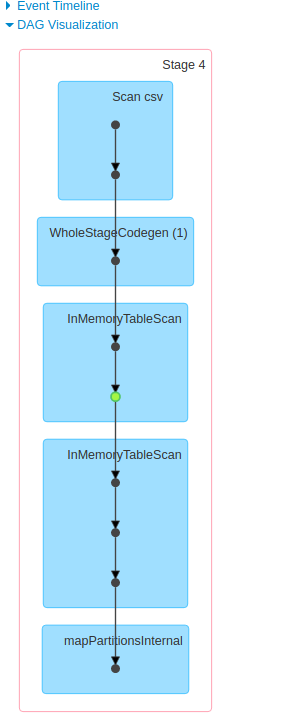
Which, when navigated into, provides more details about the query which has been cached, as well as the action where it was first computed:

It may be hard to see in the image, but notice "[Cached
count at.." at the end of the query information, as count was the first action function to be called after calling cache (Note: calling cache itself doesn't perform an action - it just ensures that when an action function is called such as count or show, the data will be cached for subsequent actions).
CodePudding user response:
any intermediate results (data) in memory?
What intermediate result do you mean? Spark will perform optimizes analysis automatically and pack a bunch of operations if there is some unnecessary intermediate result, it does not need to calculate it out. For example in your code, line1 and line2 do not take action until line 3 is executed.
That means until line2, df and df1 are kind of the "intermediate result" I guess you mean. But they actually do not even been calculated. So they are not in memory at all. The file read operation also does not perform.
However, it is different for line3, cause line3 explicitly checks the value of the df1. Then df1 could not be optimized out and its value needs to be calculated. And df1 will be in memory with its values.
does it remove from the memory?
As line3 explicitly views df1's value, the variable df1 would be in memory.
does the spark read 'example.csv' again?
No. When calling df1.show again, Spark directly reads the value from the memory.
CodePudding user response:
DAG was constructed upon operations on the dataframe. When an action is encountered spark engine executes the DAG. In your case, upon calling df.show() again spark will read the 'example.csv' again as the dataframe was not persisted/cached.