I need to filter/subdivide a dataframe considering two parameters (for exclusion) that are in a dbl_df list (39 obs; below are the first ones to exemplify).
parameters <- structure(list(V1 = c("A", "A", "B", "C"), V2 = c(2018, 2019,
2020, 2019)), row.names = c(NA, -4L), class = c("tbl_df", "tbl",
"data.frame"))
Both V1 and V2 are contained in the df to be filtered.
df <- structure(list(V_L = c("AS", "AS", "EU", "AF", "AS", "AM", "EU",
"EU"), V1 = c("A", "A", "B", "C", "A", "D", "B", "C"), V2 = c(2018,
2019, 2020, 2019, 2021, 2019, 2019, 2020), value = c(12, 13,
14, 11, 8, 16, 14, 20)), row.names = c(NA, -8L), spec = structure(list(
cols = list(V_L = structure(list(), class = c("collector_character",
"collector")), V1 = structure(list(), class = c("collector_character",
"collector")), V2 = structure(list(), class = c("collector_double",
"collector")), value = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), delim = "\t"), class = "col_spec"), problems = <pointer: 0x000001f92fdddf90>, class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"))
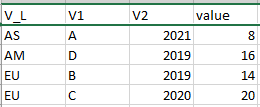
df_filtered:
I believe I have come close with help in other questions here on the forum, however I believe with the map_df function I am looking at the end of a bind rows.
map_df(parameters, ~ df %>% filter(!V1 == .x[2] & !V2 == .x[2]))
Can anyone troubleshoot or suggest another more operational proposal.
CodePudding user response:
Loading data (the given df didn't load for me without tweaking)
parameters <- structure(list(V1 = c("A", "A", "B", "C"), V2 = c(2018, 2019,
2020, 2019)), row.names = c(NA, -4L), class = c("tbl_df", "tbl",
"data.frame"))
df <- structure(list(V_L = c("AS", "AS", "EU", "AF", "AS", "AM", "EU",
"EU"), V1 = c("A", "A", "B", "C", "A", "D", "B", "C"), V2 = c(2018,
2019, 2020, 2019, 2021, 2019, 2019, 2020), value = c(12, 13,
14, 11, 8, 16, 14, 20)), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -8L))
I'd suggest using an anti join, which will return all rows from df which do not match to a row of parameters.
dplyr::anti_join(df, parameters)
Joining, by = c("V1", "V2")
# A tibble: 4 × 4
V_L V1 V2 value
<chr> <chr> <dbl> <dbl>
1 AS A 2021 8
2 AM D 2019 16
3 EU B 2019 14
4 EU C 2020 20