My dataframe (df) is a 12 months data. One of the columns is day_of_week which are Sunday to Saturday. This df also has a unique key which is the ride_id column. I want to calculate the average number of rides per day_of_week. I have calculated the number of rides per day_of_week using
copydf.groupby(['day_of_week']).agg(number_of_rides=('ride_id', 'count'))
However, I find it hard to calculate the mean/average for each day of week. I have tried:
copydf.groupby(['day_of_week']).agg(number_of_rides=('ride_id', 'count')).mean()
and
avg_days = copydf.groupby(['day_of_week']).agg(number_of_rides=('ride_id', 'count'))
avg_days.groupby(['day_of_week']).agg('number_of_rides', 'mean')
They didn't work. I want the output to be in three columns, day_of_week, number_of_rides, and avg_num_of_ride
CodePudding user response:
Using pivot we can solve this.
import pandas as pd
import numpy as np
df = pd.read_csv('/content/test.csv')
df.head()
# sample df
date rides
0 2019-10-01 1
1 2019-10-02 2
2 2019-10-03 5
3 2019-10-04 3
4 2019-10-05 2
df['date] = pd.to_datetime(df['date'])
# extracting the week Number
df['weekNo'] = df['date'].dt.week
date rides weekNo
0 2019-10-01 1 40
1 2019-10-02 2 40
2 2019-10-03 5 40
Method 1: Use Pivot table
df.pivot_table(values='rides',index='weekNo',aggfunc='mean')
output
rides
weekNo
40 2.833333
41 2.571429
42 4.000000
Method 2: Use groupby.mean()
df.groupby('weekNo')['rides'].mean()
CodePudding user response:
As far as I understand, you're not trying to compute the average over a field in your grouped data (as @Azhar Khan pointed out), but an averaged count of rides per weekday over your original 12-months period.
Basically, you need two elements:
- First, the count of rides per weekday you observe in your dataframe. That's exactly what you get with
copydf.groupby(['day_of_week']).agg(number_of_rides=('ride_id', 'count'))Let's say you get something like:
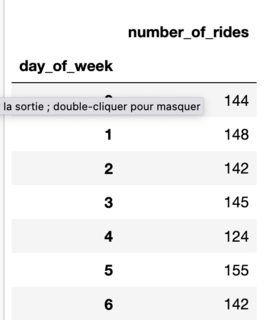
- Secondly, the count of weekdays in your period. Let's imagine you're considering the year 2022 as an example, you can get such data with the next code snippet:
df_year = pd.DataFrame(data=pd.date_range(start=pd.to_datetime('01-01-2022'),
end=pd.to_datetime('31-12-2022'),
freq='1D'),
columns=['date'])
df_year["day_of_week"] = df_year["date"].dt.weekday
nb_weekdays_in_year = df_year.groupby('day_of_week').agg(nb_days=('date', 'count'))
This gives such a dataframe:
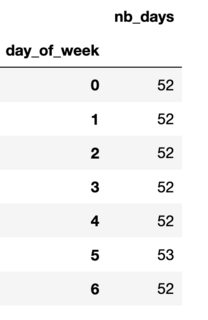
Once you have both these dataframes, you can simply join them with
nb_weekdays_in_year.join(nb_rides_per_day) for instance, and you just need to perform the ratio of both colums to get your average.
The difficulty here lies in the fact you need to get the total number of weekdays of each type over your period, that you cannot get from your observation directly I guess (what if there's some missing value ?). Plus, let's underline you're not trying to get an intra-group average, so that you cannot use simple agg functions like 'mean' directly.