I have a dataset that has a column containing a list of dictionaries. I want to split the column into keys as columns and fill in the values
edit: every cell in the column contains a list of dictionaries, I want to split them into the same row
sample of the data:
[{'genre': 'Adventure, Indie, RPG',
'item_id': '326950',
'discounted_price': '$8.99',
'item_url': 'http://store.steampowered.com/app/326950',
'item_name': 'Sword of Asumi'},
{'genre': 'Adventure, Indie, RPG',
'item_id': '331490',
'discounted_price': '$2.99',
'item_url': 'http://store.steampowered.com/app/331490',
'item_name': 'Sword of Asumi - Soundtrack'}]
The output that I want to be like :
| genre_0 | item_id_0 | discounted_price_0 | item_url_0 | item_name_0 | genre_1 | item_id_1 | ....etc |
|---|---|---|---|---|---|---|---|
| One | Two | Three | One | Two | Three | One | ---- |
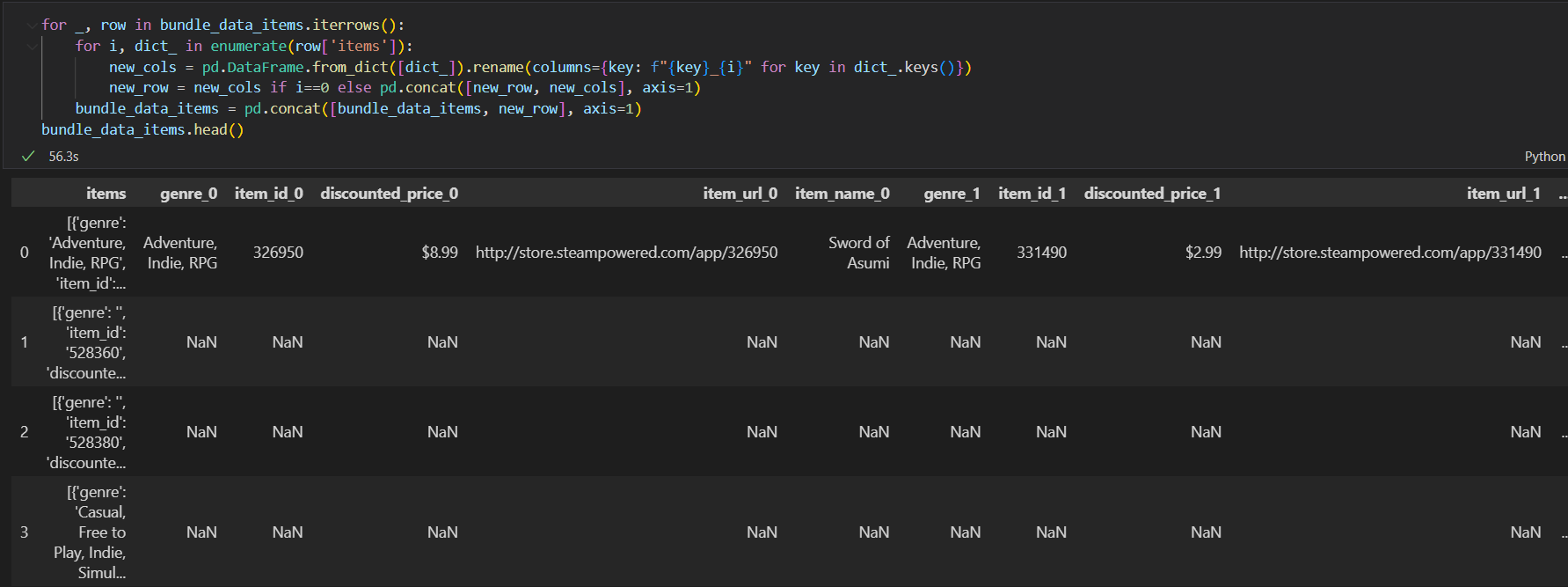
CodePudding user response:
You can use pd.DataFrame.from_dict like this:
import pandas as pd
df = pd.DataFrame()
df['data'] = [[{'genre': 'Adventure, Indie, RPG',
'item_id': '326950',
'discounted_price': '$8.99',
'item_url': 'http://store.steampowered.com/app/326950',
'item_name': 'Sword of Asumi'},
{'genre': 'Adventure, Indie, RPG',
'item_id': '331490',
'discounted_price': '$2.99',
'item_url': 'http://store.steampowered.com/app/331490',
'item_name': 'Sword of Asumi - Soundtrack'}]]
df2 = df.copy()
for _, row in df.iterrows():
for i, dict_ in enumerate(row['data']):
new_cols = pd.DataFrame.from_dict([dict_]).rename(columns={key: f"{key}_{i}" for key in dict_.keys()})
new_row = new_cols if i==0 else pd.concat([new_row, new_cols], axis=1)
df2 = pd.concat([df2, new_row], axis=1)
print(df2.columns)
Index(['data', 'genre_0', 'item_id_0', 'discounted_price_0', 'item_url_0',
'item_name_0', 'genre_1', 'item_id_1', 'discounted_price_1',
'item_url_1', 'item_name_1'],
dtype='object')
CodePudding user response:
I created a function to solve this problem
function to split the list of dictionaries in a column
def split_list(df, column):
for _, row in df.iterrows():
for i , dict_ in enumerate(row[column]):
for key, value in dict_.items():
df.loc[_, column '_' key '_' str(i)] = value
# drop columns with more than 50% missing values
df.dropna(axis=1, thresh=df.shape[0]*0.5, inplace=True)
return df
CodePudding user response:
You can use concat of dataframes created from list comprehension like below:
lst = [{'genre': 'Adventure, Indie, RPG',
'item_id': '326950',
'discounted_price': '$8.99',
'item_url': 'http://store.steampowered.com/app/326950',
'item_name': 'Sword of Asumi'},
{'genre': 'Adventure, Indie, RPG',
'item_id': '331490',
'discounted_price': '$2.99',
'item_url': 'http://store.steampowered.com/app/331490',
'item_name': 'Sword of Asumi - Soundtrack'}]
pd.concat([pd.DataFrame(d, index=[0]).rename(('{}_' str(i)).format,
axis=1) for i, d in enumerate(lst)], axis=1)
output:
genre_0 item_id_0 discounted_price_0 item_url_0 item_name_0 genre_1 item_id_1 discounted_price_1 item_url_1 item_name_1
0 Adventure, Indie, RPG 326950 $8.99 http://store.steampowered.com/app/326950 Sword of Asumi Adventure, Indie, RPG 331490 $2.99 http://store.steampowered.com/app/331490 Sword of Asumi - Soundtrack