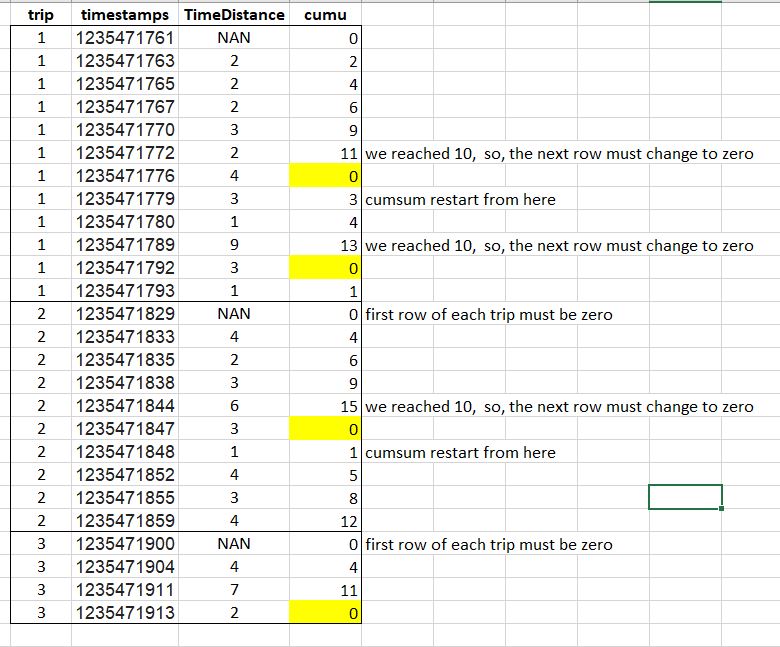
I have a dataframe like this:
import pandas as pd
import numpy as np
data={'trip':[1,1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,3,3,3,3],
'timestamps':[1235471761, 1235471763, 1235471765, 1235471767, 1235471770, 1235471772, 1235471776, 1235471779, 1235471780, 1235471789,1235471792,1235471793,1235471829,1235471833,1235471835,1235471838,1235471844,1235471847,1235471848,1235471852,1235471855,1235471859,1235471900,1235471904,1235471911,1235471913]}
df = pd.DataFrame(data)
df['TimeDistance'] = df.groupby('trip')['timestamps'].diff(1)
df
What I am looking for is to start from the first row(consider it as an origin) in the "TimeDistance" column and doing cumulative sum over its values and whenever this summation reach 10, restart the cumsum and continue this procedure until the end of the trip (as you can see in this dataframe we have 3 trips in the "trip" column). I want all the cumulative sum in a new column,lets say, "cumu" column. Another important issue is that after reaching out threshold, the next row after threshold in the "cumu" column must be zero and the summation restart from this new origin again.
CodePudding user response:
I hope I've understood your question right. You can use generator with .send():
def my_accumulate(maxval):
val = 0
yield
while True:
if val < maxval:
val = yield val
else:
yield val
val = 0
def fn(x):
a = my_accumulate(10)
next(a)
x["cumu"] = [a.send(v) for v in x["TimeDistance"]]
return x
df = df.groupby("trip").apply(fn)
print(df)
Prints:
trip timestamps TimeDistance cumu
0 1 1235471761 NaN 0.0
1 1 1235471763 2.0 2.0
2 1 1235471765 2.0 4.0
3 1 1235471767 2.0 6.0
4 1 1235471770 3.0 9.0
5 1 1235471772 2.0 11.0
6 1 1235471776 4.0 0.0
7 1 1235471779 3.0 3.0
8 1 1235471780 1.0 4.0
9 1 1235471789 9.0 13.0
10 1 1235471792 3.0 0.0
11 1 1235471793 1.0 1.0
12 2 1235471829 NaN 0.0
13 2 1235471833 4.0 4.0
14 2 1235471835 2.0 6.0
15 2 1235471838 3.0 9.0
16 2 1235471844 6.0 15.0
17 2 1235471847 3.0 0.0
18 2 1235471848 1.0 1.0
19 2 1235471852 4.0 5.0
20 2 1235471855 3.0 8.0
21 2 1235471859 4.0 12.0
22 3 1235471900 NaN 0.0
23 3 1235471904 4.0 4.0
24 3 1235471911 7.0 11.0
25 3 1235471913 2.0 0.0
Another solution:
df = df.groupby("trip").apply(
lambda x: x.assign(
cumu=(
val := 0,
*(
val := val v if val < 10 else (val := 0)
for v in x["TimeDistance"][1:]
),
)
),
)
print(df)
CodePudding user response:
Andrej's answer is better, as mine is probably not as efficient, and it depends on the df being ordered by trip and the TimeDistance being nan as the first value of each trip.
cummulative_sum = 0
df['cumu'] = 0
for i in range(len(df)):
if np.isnan(df.loc[i,'TimeDistance']) or cummulative_sum >= 10:
cummulative_sum = 0
df.loc[i, 'cumu'] = 0
else:
cummulative_sum = df.loc[i,'TimeDistance']
df.loc[i, 'cumu'] = cummulative_sum
print(df) outputs:
trip timestamps TimeDistance cumu
0 1 1235471761 NaN 0
1 1 1235471763 2.0 2
2 1 1235471765 2.0 4
3 1 1235471767 2.0 6
4 1 1235471770 3.0 9
5 1 1235471772 2.0 11
6 1 1235471776 4.0 0
7 1 1235471779 3.0 3
8 1 1235471780 1.0 4
9 1 1235471789 9.0 13
10 1 1235471792 3.0 0
11 1 1235471793 1.0 1
12 2 1235471829 NaN 0
13 2 1235471833 4.0 4
14 2 1235471835 2.0 6
15 2 1235471838 3.0 9
16 2 1235471844 6.0 15
17 2 1235471847 3.0 0
18 2 1235471848 1.0 1
19 2 1235471852 4.0 5
20 2 1235471855 3.0 8
21 2 1235471859 4.0 12
22 3 1235471900 NaN 0
23 3 1235471904 4.0 4
24 3 1235471911 7.0 11
25 3 1235471913 2.0 0