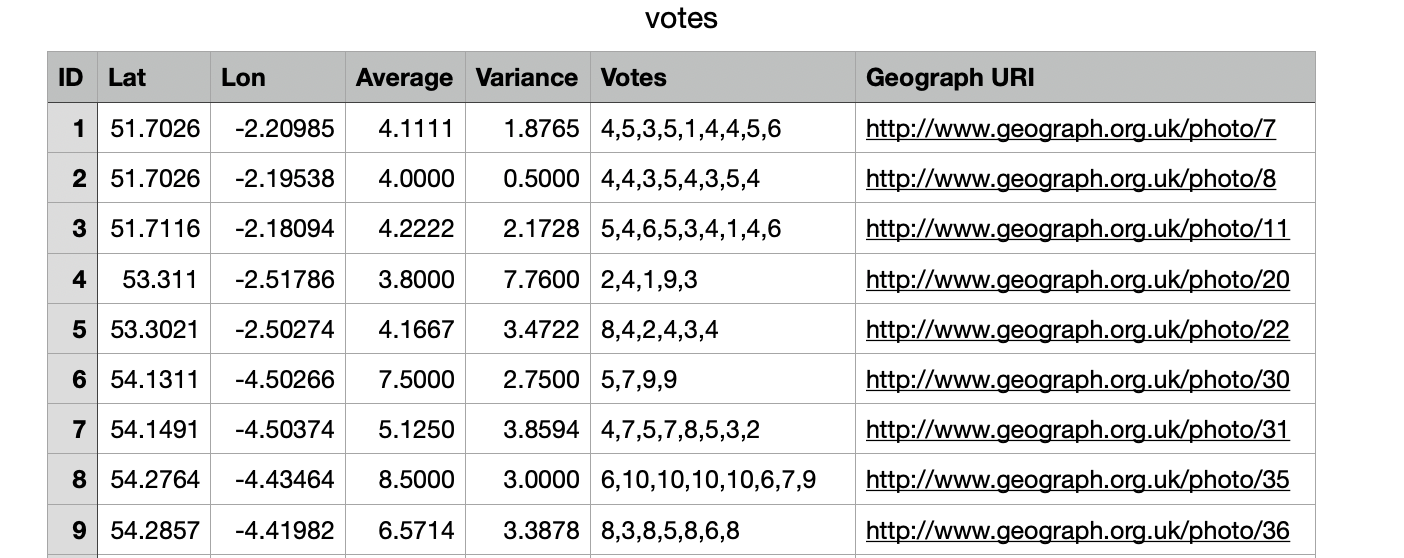
I want to find out the mean of each row for column "votes" but when I try to read that column in as a numeric value instead of a character it gives me an error. After that I dont know how to get r to understand what i want !
CodePudding user response:
When reading a CSV file where a field as comma-delimited numbers, it will always be string, it cannot be read as a number. This is because "what number" is ambiguous, so R will make you choose. There are such things as list-columns that will allow each field to be a list of numbers, but most vector-based functions will not work as smoothly on them.
Since it is likely to be read as numbers, we can split it manually with this:
dat <- data.frame(Votes = c("4,5,3,5,1,4,4,5,6", "4,4,3,5,4,3,5,4", "5,4,6,5,3,4,1,4,6"))
dat
# Votes
# 1 4,5,3,5,1,4,4,5,6
# 2 4,4,3,5,4,3,5,4
# 3 5,4,6,5,3,4,1,4,6
dat$Votes_mu <- sapply(strsplit(dat$Votes, ","), function(z) mean(as.numeric(z)))
dat
# Votes Votes_mu
# 1 4,5,3,5,1,4,4,5,6 4.111111
# 2 4,4,3,5,4,3,5,4 4.000000
# 3 5,4,6,5,3,4,1,4,6 4.222222
Note: if there are any non-numbers (non-response or non-numeric characters), then mean(as.numeric(.)) will produce an NA. If you want to ignore the non-numbers, then change the inner code to mean(as.numeric(z), na.rm = TRUE).
Extra: list-columns
FYI, the "list-column" thing in R can be a good way to store multiple values, especially when (as in this example) there are different amounts per row. In this case, we can do something like:
dat$Votes2 <- lapply(strsplit(dat$Votes, ","), as.numeric)
dat
# Votes Votes2
# 1 4,5,3,5,1,4,4,5,6 4, 5, 3, 5, 1, 4, 4, 5, 6
# 2 4,4,3,5,4,3,5,4 4, 4, 3, 5, 4, 3, 5, 4
# 3 5,4,6,5,3,4,1,4,6 5, 4, 6, 5, 3, 4, 1, 4, 6
And while they look really similar (albeit spaces), you can see the structural differences:
str(dat)
# 'data.frame': 3 obs. of 2 variables:
# $ Votes : chr "4,5,3,5,1,4,4,5,6" "4,4,3,5,4,3,5,4" "5,4,6,5,3,4,1,4,6"
# $ Votes2:List of 3
# ..$ : num 4 5 3 5 1 4 4 5 6
# ..$ : num 4 4 3 5 4 3 5 4
# ..$ : num 5 4 6 5 3 4 1 4 6
This might be helpful if you need to find specific tokens (votes) in each element. For instance, if you wanted to know which rows had at least one 1 vote, then one could do:
sapply(dat$Votes2, function(z) 1 %in% z)
# [1] TRUE FALSE TRUE
(where this method does not work with dat$Votes). Yes, this one example could use regex to find 1s in Votes, so perhaps list-columns aren't necessary for your use-case.
CodePudding user response:
Here are two equivalent ways.
dat <- data.frame(Votes = c("4,5,3,5,1,4,4,5,6", "4,4,3,5,4,3,5,4",
"5,4,6,5,3,4,1,4,6"))
sapply(dat$Votes, \(x) mean(scan(textConnection(x), sep = ",")), USE.NAMES = FALSE)
#> [1] 4.111111 4.000000 4.222222
dat$Votes |>
sapply(\(x) x |> textConnection() |> scan(sep = ",") |> mean(), USE.NAMES = FALSE)
#> [1] 4.111111 4.000000 4.222222
Created on 2022-10-25 with reprex v2.0.2
CodePudding user response:
1) Using DF in the Note at the end, scan each comma separated value by row (which for each row will create a numeric vector of those numbers) and then take the mean of that vector.
library(dplyr)
DF %>%
rowwise %>%
mutate(mean = mean(scan(text = y, sep = ",", quiet = TRUE))) %>%
ungroup
giving:
# A tibble: 3 × 3
x y mean
<int> <chr> <dbl>
1 1 1,2,3 2
2 2 4,5 4.5
3 3 7 7
2) Using only base R:
Mean <- function(x) mean(scan(text = x, sep = ",", quiet = TRUE))
transform(DF, mean = sapply(y, Mean))
3) Another base R approach:
transform(DF,
mean = rowMeans(read.table(text = y, fill = TRUE, sep = ","), na.rm = TRUE))
Note
DF <- data.frame(x = 1:3, y = c("1,2,3", "4,5", "7"))
> DF
x y
1 1 1,2,3
2 2 4,5
3 3 7