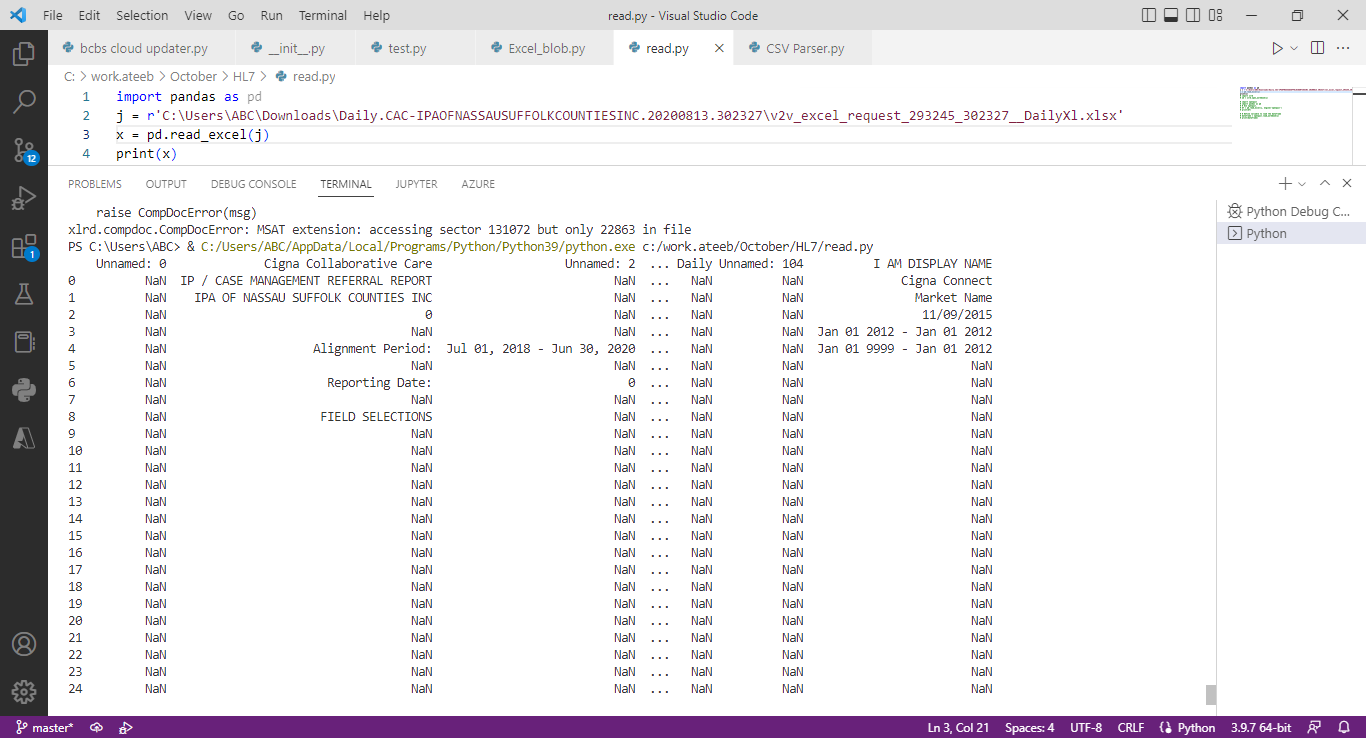
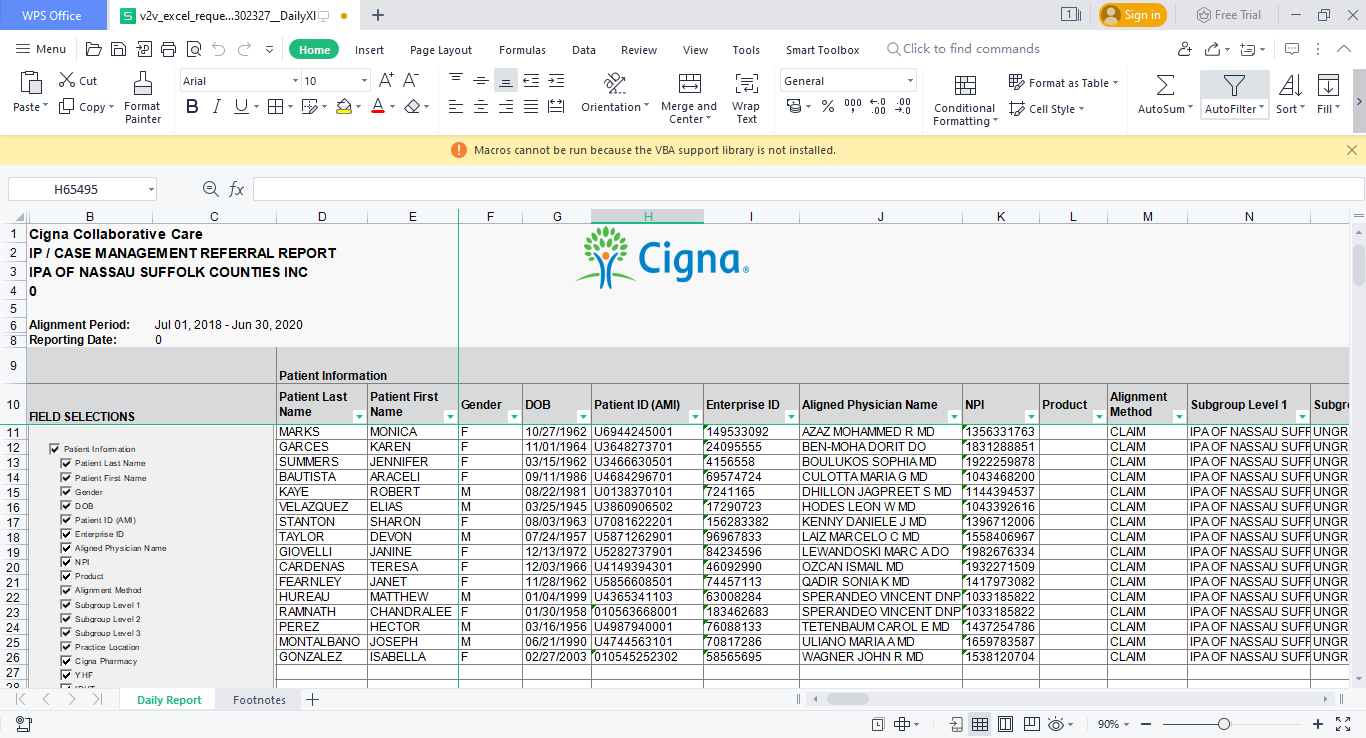
I am unable to read this type of excel file from pandas in python.
CodePudding user response:
Although cannot understand your situation best from picture.
Still recommend to Try to read file with following code might help, where you need to add extra parameters which will help to filter some unnecessary info.
pd.read_excel(full_path, sheet_name = 'Daily Report', skiprows = <rowsyouwnttoskip>, nrows= <yourlastrow>, usecols = f'D:Z')
note: I havenot add the exact value in above code, edit as per your need
Then you need to apply addition cleaning such as take your first row as column names, and etc.
Update: you can use additonal function as below
def convert_xls_to_xlsx(p , f): #P stands for Path and F for file name with extension
oldFile = os.path.abspath(p '\\' f)
newFile = os.path.abspath(p '\\' f[:f.find('.')])
xlApp = Dispatch('Excel.Application')
wb = xlApp.Workbooks.Open(oldFile)
wb.SaveAs(newFile,51)
wb.Close(True)
os.remove(oldFile)
CodePudding user response:
You can read xlsx file using openpyxl engine.
import pandas as pd
df = pd.read_excel('C://Users//jahir//Desktop//file_name.xlsx', engine='openpyxl')
print(df)