I wonder if there is an easy way to achieve what I want. Basically, I want to remove duplicated data from a DataFrame and store two records in one, creating a new column new_value2 where I will store one value from other record that comply certain condition.
I have a DataFrame where the column key2 can have a duplicated value, two duplicates as much. If this is the case, and the column value2 in the same row is equal to copy, then what I want is to move the value in column value to the column new_value2 of the record where the key2 column has the same value (but the value2 colum value is NaN).
I think you will understand better looking at the image:
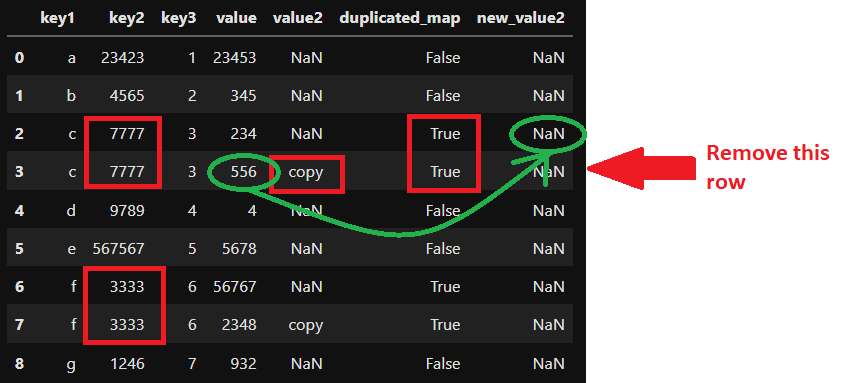
I forgot to add the key1 and key3 to the subset as you can check in this source code:
import pandas as pd
import numpy as np
df = pd.DataFrame({
'key1': ['a', 'b', 'c', 'c', 'd', 'e', 'f', 'f', 'g'],
'key2': [23423, 4565, 7777, 7777, 9789, 567567, 3333, 3333, 1246],
'key3': [1, 2, 3, 3, 4, 5, 6, 6, 7],
'value': [23453, 345, 234 ,556, 4, 5678, 56767, 2348, 932],
'value2': [np.nan, np.nan, np.nan, 'copy', np.nan, np.nan, np.nan, 'copy', np.nan]
})
df['duplicated_map'] = df.duplicated(subset=['key1', 'key2', 'key3'], keep=False)
df['new_value2'] = np.nan # ??
df
Finally I would like to remove the original row where I took the value.
CodePudding user response:
If there are at most two duplicate values, you can do groupby.apply
def set_value(g):
if len(g) > 1:
g.loc[g['value2'].ne('copy'), 'new_value2'] = g.loc[g['value2'].eq('copy'), 'value'].values
return g[g['value2'].ne('copy')]
else:
return g
out = df.groupby('key2').apply(set_value).reset_index(drop=True)
print(out)
key1 key2 key3 value value2 new_value2
0 g 1246 7 932 NaN NaN
1 f 3333 6 56767 NaN 2348.0
2 b 4565 2 345 NaN NaN
3 c 7777 3 234 NaN 556.0
4 d 9789 4 4 NaN NaN
5 a 23423 1 23453 NaN NaN
6 e 567567 5 5678 NaN NaN