My sample data set looks like this.
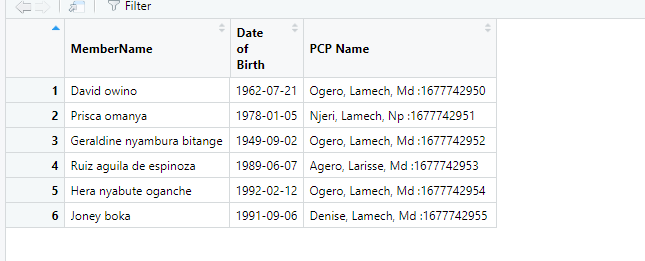
Reproducible Sample Data
dput(head(Sample_Dataset))
structure(list(MemberName = c("David owino", "Prisca omanya",
"Geraldine nyambura bitange", "Ruiz aguila de espinoza", "Hera nyabute oganche",
"Joney boka"), `Date of Birth` = structure(c(-235094400, 252806400,
-641606400, 613180800, 697852800, 684115200), tzone = "UTC", class = c("POSIXct",
"POSIXt")), `PCP Name` = c("Ogero, Lamech, Md :1677742950", "Njeri, Lamech, Np :1677742951",
"Ogero, Lamech, Md :1677742952", "Agero, Larisse, Md :1677742953",
"Ogero, Lamech, Md :1677742954", "Denise, Lamech, Md :1677742955"
)), row.names = c(NA, -6L), class = c("tbl_df", "tbl", "data.frame"
))
#Splitting
String <- stringr::str_split(Sample_Dataset$MemberName, "[ ]", n = 2)
Last_Name <- sapply(String, '[', -1)
First_Name <- sapply(String, '[', 1)
Sample_d2 <-data.frame(First_Name, Last_Name)
The first part split it into first names and last names had 2 - 3 names (for individuals with 4 names)
names.split <- strsplit(unlist(Sample_d2$Last_Name), " ")
Middle_Names <- sapply(names.split$Last_Name, function(x)
if(length(String$Last_Name) == 2) {
Middle_Names <- sapply(String, '[', 1)
} else if (length(String$Last_Name) == 3){
Middle_Names<- sapply(String, '[', 1:2)
}
)
Sample_d2 <- data.frame(First_Name,Middle_Names, Last_Name)
I want to extract first name, last name and everything else be middle names.
CodePudding user response:
Here is an option. I can update with some optional qualifiers for the last such as "de" later:
library(tidyverse)
dat <- tibble(name = c("John Tyler Smith", "Bryan Alexander", "Sarah Mary Thomas", "Tommy Hawk"))
extract(dat,
col = name,
into = c("first", "middle", "last"),
regex = "^(\\w )(?:\\s)?(\\w )?\\s(\\w $)",
remove = FALSE)
#> # A tibble: 4 x 4
#> name first middle last
#> <chr> <chr> <chr> <chr>
#> 1 John Tyler Smith John "Tyler" Smith
#> 2 Bryan Alexander Bryan "" Alexander
#> 3 Sarah Mary Thomas Sarah "Mary" Thomas
#> 4 Tommy Hawk Tommy "" Hawk
CodePudding user response:
Here is another way that you can go about extracting parts of names. Just note that I create 3 capturing groups but made the the second one lazy as there might not be a match (no middle name):
library(tidyr)
df %>%
extract(MemberName, into = c('First', 'Middle', 'Last'),
regex = '(^[A-Z][a-z] )(?:\\s([a-z ] ))?(?:\\s )([a-z] )')
# A tibble: 6 × 5
First Middle Last `Date of Birth` `PCP Name`
<chr> <chr> <chr> <dttm> <chr>
1 David "" owino 1962-07-21 00:00:00 Ogero, Lamech, Md :1677742950
2 Prisca "" omanya 1978-01-05 00:00:00 Njeri, Lamech, Np :1677742951
3 Geraldine "nyambura" bitange 1949-09-02 00:00:00 Ogero, Lamech, Md :1677742952
4 Ruiz "aguila de" espinoza 1989-06-07 00:00:00 Agero, Larisse, Md :1677742953
5 Hera "nyabute" oganche 1992-02-12 00:00:00 Ogero, Lamech, Md :1677742954
6 Joney "" boka 1991-09-06 00:00:00 Denise, Lamech, Md :1677742955