I have a data model with two tables sharing the same columns. I have merged the tables using the prefixes "Old." and "New." I'd like to add a calculated column for each column that shows if the values are different with the name like "Column_IsDifferent" and a boolean value of true or false.
I have already found out that you can add multiple columns by using List.Accumulate. But for some reason my code seems not to work as expected:
= List.Accumulate(List.Select(Table.ColumnNames(#"Extend joined table"), each Text.StartsWith(_, "New")), #"Extend joined table", (state, current) => Table.AddColumn(state, Text.RemoveRange(current, 0, 4) & "_IsDifferent", each Table.Column(state, current) <> Table.Column(state, "Old." & Text.RemoveRange(current, 0, 4)), type logical))
Basically, it takes forever to load data and I don't get an error message...
I suspect there is something wrong with this part:
Table.Column(state, current) <> Table.Column(state, "Old." & Text.RemoveRange(current, 0, 4))
CodePudding user response:
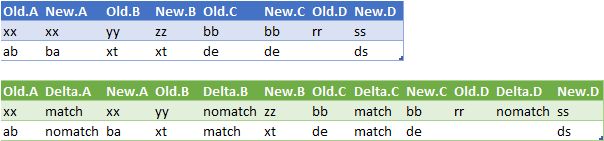
You can try this in powerquery which adds a 3rd column to each 2 column pair showing if they match
let Source = Excel.CurrentWorkbook(){[Name="Table1"]}[Content],
#"Added Index" = Table.AddIndexColumn(Source, "Index", 0, 1, Int64.Type),
#"Unpivoted Other Columns" = Table.UnpivotOtherColumns(#"Added Index", {"Index"}, "Attribute", "Value"),
#"Duplicated Column" = Table.DuplicateColumn(#"Unpivoted Other Columns", "Attribute", "Attribute - Copy"),
#"Split Column by Delimiter" = Table.SplitColumn(#"Duplicated Column", "Attribute - Copy", Splitter.SplitTextByDelimiter(".", QuoteStyle.Csv), {"A1", "A2"}),
#"Grouped Rows" = Table.Group(#"Split Column by Delimiter", {"Index", "A2"}, {{"data", each
let compare = if _{0}[Value] = _{1}[Value] then "match" else "nomatch"
in Table.InsertRows( _,1,{[Index = _{0}[Index], Attribute = "Delta."&_{0}[A2], Value=compare, A1="Delta", A2=_{0}[A2]]})
, type table }}),
#"Expanded data" = Table.ExpandTableColumn(#"Grouped Rows", "data", {"Attribute", "Value" }, {"Attribute", "Value"}),
#"Removed Columns" = Table.RemoveColumns(#"Expanded data",{"A2"}),
#"Pivoted Column" = Table.Pivot(#"Removed Columns", List.Distinct(#"Removed Columns"[Attribute]), "Attribute", "Value"),
#"Removed Columns1" = Table.RemoveColumns(#"Pivoted Column",{"Index"})
in #"Removed Columns1"
CodePudding user response:
Just stumbled upon something, what do you think about this change:
each Table.Column(state, current) <> Table.Column(state, "Old." & Text.RemoveRange(current, 0, 4))
into:
each Record.Field(_, current) <> Record.Field(_, "Old." & Text.RemoveRange(current, 0, 4))