I have a dataframe that looks like this:
ID Age Score
0 9 5 3
1 4 6 1
2 9 7 2
3 3 2 1
4 12 1 15
5 2 25 6
6 9 5 4
7 9 5 61
8 4 2 12
I want to sort based on the first column, then the second column, and so on.
So I want my output to be this:
ID Age Score
5 2 25 6
3 3 2 1
8 4 2 12
1 4 6 1
0 9 5 3
6 9 5 4
7 9 5 61
2 9 7 2
4 12 1 15
I know I can do the above with df.sort_values(df.columns.to_list()), however I'm worried this might be quite slow for much larger dataframes (in terms of columns and rows).
Is there a more optimal solution?
CodePudding user response:
You can use 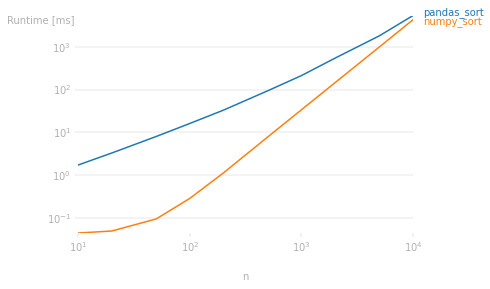
Same graph with the speed relative to pandas
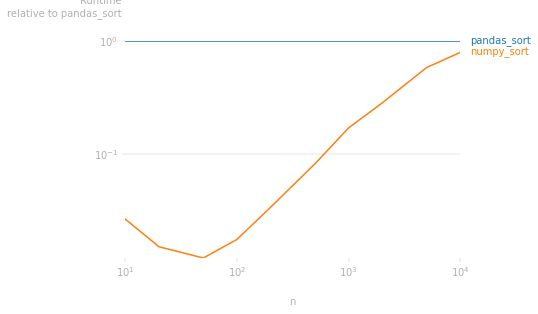
CodePudding user response:
By still using df.sort_values() you can speed it up a bit by selecting the type of sorting algorithm. By default it's set to quicksort, but there is the alternatives of 'mergesort', 'heapsort' and 'stable'.
Maybe specifying one of these would improve it?
df.sort_values(df.columns.to_list(), kind="mergesort")
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html