I have a filtered time series dataframe. When I see the missing datetime columns, the figure obtained is as below:
df.datetime.diff().plot()
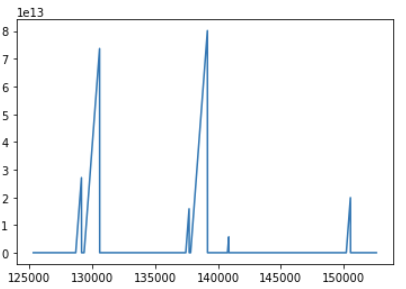
Here, I can manually see the missing datetime values as the spikes. Is there a way to get the start and stop of these datetime column, if for example they are missing for more than one minute?
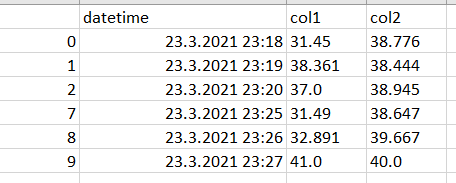
Example dataframe:
dic = {
'datetime' : [23.3.2021 23:18:00, 23.3.2021 23:19:00, 23.3.2021 23:20:00, 23.3.2021 23:25:00, 23.3.2021 23:26:00, 23.3.2021 23:27:00],
'col1':[31.45,38.361,37.0,31.49,32.891, 41],
'col2':[38.776,38.444,38.945,38.647,39.667,40.0],
}
df=pd.DataFrame(dic)
CodePudding user response:
You can use:
# ensure datetime
df['datetime'] = pd.to_datetime(df['datetime'])
# identify values above 1min
m = df['datetime'].diff().gt('1min')
# group the consecutive values above threshold
out = (df.loc[m, 'datetime'].groupby((~m).cumsum())
.agg(start='min', stop='max')
.reset_index(drop=True)
)
output:
start stop
0 2021-03-23 23:25:00 2021-03-23 23:25:00