There is main dataframe: dfMain.
I need to select from this 2 pieces of data for applying to each one 2 different operations. And know in advance, that one piece (selected by A-criteria) is large, than another one.
Which way is more effective:
Select the large piece of data, and then except selected data from dfMain (to retrieve the smaller piece).
val large = dfMain.filter(col("data")==="criteriaA") large.persist(StorageLevel.MEMORY_AND_DISK) large .write .parquet("storeA") dtMain.except(large) .write .parquet("storeB")Select the small piece of data, and then except selected data from dfMain (to retrieve the large piece).
val small = dfMain.filter(col("data")==="criteriaB") small.persist(StorageLevel.MEMORY_AND_DISK) small .write .parquet("storeB") dtMain.except(small) .write .parquet("storeA")
Something tells me, that first way cheaper, but I have some doubts
CodePudding user response:
maybe it will be better to create two separate df with two separate filters
val small = dfMain.filter(col("data")==="criteriaB")
val large = dfMain.filter(col("data")==="criteriaA")
//and later do what you want and store them separately
when you use except i think that i will be resolved to anti-join and i think that two filters are going to be more efficient if you just want to split df into two parts
Edit: i did one simple test, here is sample code
import org.apache.spark.sql.functions._
import org.apache.spark.storage.StorageLevel
spark.conf.set("spark.sql.shuffle.partitions", "10")
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val data = Seq(("test", 3),("test", 3), ("test2", 5), ("test3", 7), ("test55", 86))
val dfMain = data.toDF("Name", "Value")
val large = dfMain.filter(col("Value")===lit(5))
large.persist(StorageLevel.MEMORY_AND_DISK)
large.show
dfMain.except(large).show
I changed writes to show but is shouldnt change anything, type of actions has no effect here i think
autoBroadcastJoinTreshold is set to -1 to turn off broadcast join as most likely for bigger datasets its not going to be used by Spark
Here is execution plan
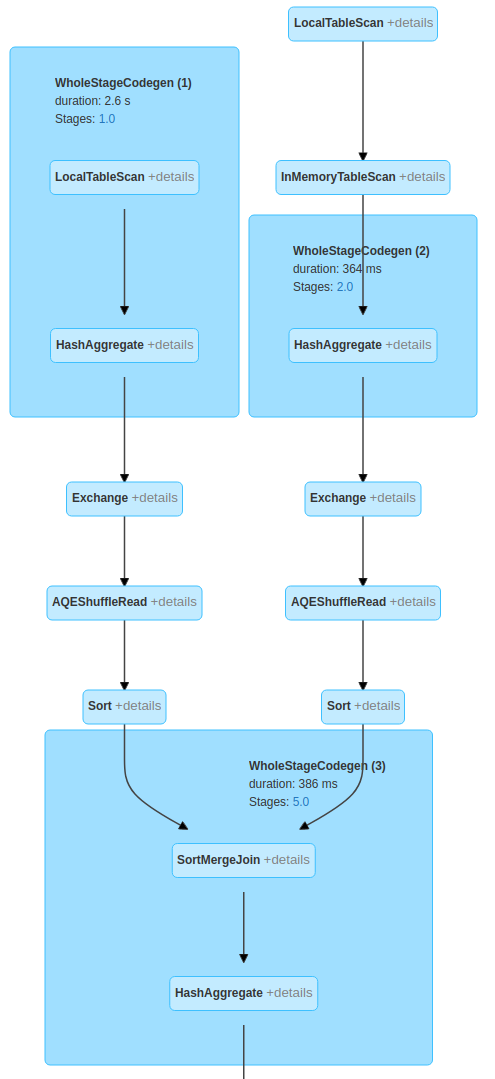
So with except Spark is going to read data two times anyway and later except is translated into left anti join for wich Spark is most likely going to choose SMJ (sort-merge join) which requires the data to be shuffled and sorted.
When i use two filters instead of except there is no need to shuffle the data, Spark is only going to read source two times (so the same as in except scenario) with two separate filters which most probably are going to be pushed to source anyway (depends on source ofc)