I have a list of 50k URL's, and am looking for the most common 3/4/5/6 letters in these URLs (barring .com/.org/etc).
So if the URLs are strings.com and string2.com, it would tell me that string is the most common sequence of letters.
Is there a way to do this?
I tried =INDEX(range, MODE(MATCH(range, range, 0 ))), but it didn't work.
CodePudding user response:
The following will spill all possible consecutive 3-6 character substrings and their count in order of their respective count:
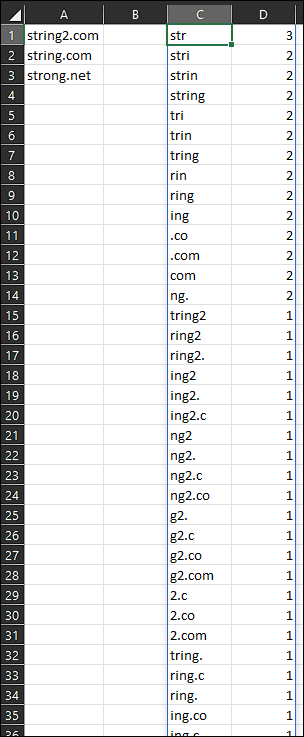
Formula in C2:
=LET(x,TOCOL(DROP(REDUCE(0,SEQUENCE(4,,3),LAMBDA(a,b,HSTACK(a,LET(c,REDUCE(0,A1:A3,LAMBDA(d,e,VSTACK(d,LET(f,MID(e,SEQUENCE(LEN(e)-b 1),b),f)))),c)))),1),2),y,UNIQUE(x),UNIQUE(SORT(HSTACK(y,MAP(y,LAMBDA(z,SUM(--(x=z))))),2,-1)))
CodePudding user response:
I am not sure to fully understand the ask. I assume you would like to find the most frequent sub-strings for a set of different sizes (6/5/4/3). Let's say your data is in column A. You would like to know the most common substrings for all possible sizes in the list.
In cell C1 we generate the expected sizes:
=TEXTSPLIT("6,5,4,3", ",")
Now from each length, we are going to find the most frequent pattern within that length from column A.
In cell C2, we are going to use the following formula:
=LET(maxLength, C1, strings, $A$2:$A$13, substr, LEFT(strings, maxLength),
match, XMATCH(substr, UNIQUE(substr)),
matchUX, UNIQUE(match), freq, DROP(FREQUENCY(match, matchUX), -1),
maxFreq, MAX(freq), matchIdx, FILTER(matchUX, ISNUMBER(XMATCH(freq, maxFreq))),
UNIQUE(FILTER(substr, ISNUMBER(XMATCH(match, matchIdx))))
)
and then expand it to the right, to consider different lengths on every column.
Here is the expected output:
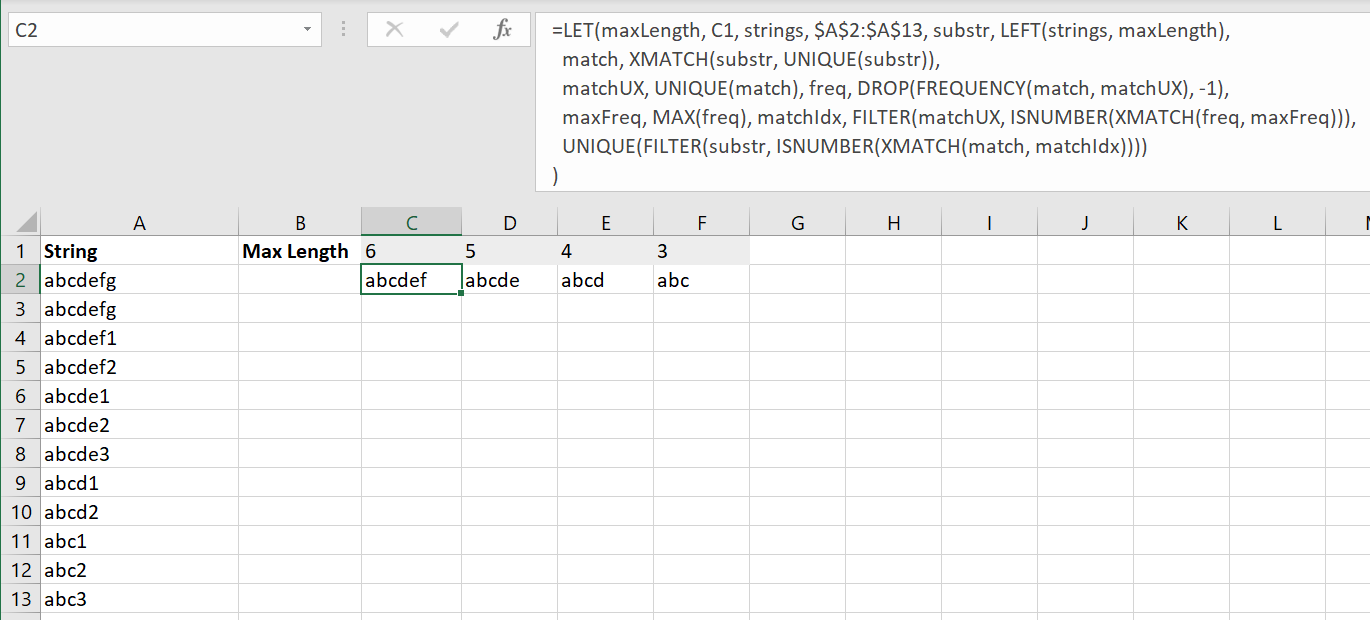
You can have more than one sub-string with the highest frequency, so it can return an array instead of a single value. In the previous example, the output is just a single value, but the formula assumes more than one sub-string can have the maximum frequency.
Explanation
On each iteration (each column), we select from the name strings the corresponding substring (based on the maximum length). We use for that LEFT function.
Because substr name is an array (not a range, we cannot use any function from the COUNTIF* family). Instead, we are going to use XMATCH/FREQUENCY because both accept arrays.
The name match:
XMATCH(substr, UNIQUE(substr))
Helps to find the counts, via: XMATCH(lookup_value, lookup_array) every time the lookup_array value is found in lookup_value, it puts the same index position.
Now with the unique number of matches (matchUX), we can do the count via FREQUENCY. We don't need the last open bins (check the documentation of this function), so we drop the last row via DROP function.
Now we have the frequency (freq), and we need to find the maximum frequency. The FREQUENCY function returns the frequency for each bin (matchUX). So we are interested in all values from matchUX that has the maximum frequency (maxFreq). We use FILTER function for that. We can have more than one filtered result, i.e. the scenario where two sub-strings have the maximum frequency.
Then the name matchIdx, has all the indexes from match name, corresponding to the maximum frequency. What we need now is to find the corresponding substr values. The names match and substr have the same size, so we can use FILTER again to find such substr values via matchIdx
using XMATCH function.
Finally, we use UNIQUE in case the maximum frequency was reached by the same substring, so we are interested only in unique substrings.