First of all, this is my data:
x <- structure(list(FIGURE = c("4", "4", "4", "4", "XXXIIIc", "XXXIIIc",
"XXXIIIc", "XXXVI", "XXXVI", "XXXVI", "XLIV", "XLIV", "XLIV",
"3", "3", "88", "88", "19", "19", "19", "19", "19", "18a", "18a",
"18a", "18b", "18c", "18c", "18c", "18c", "18c", "55", "Ensemble IX",
"2", "25", "25", "26", "26", "29", "54", "54", "130", "130"),
media_fecha = c(16382.5, 14759, 13776, 15941, 18189.5, 17546.5,
17422, 18084, 16898.5, 17987, 16422.5, 15729.5, 17615.5,
16016, 15864.5, 14643, 14132, 17146.5, 16619.5, 16424, 16317,
16328.5, 16317, 15679, 14834.5, 15467, 13197.5, 12691.5,
12683.5, 12384, 14545, 16053.5, 16669.5, 15234.5, 17036.5,
16608, 17428, 17439.5, 26785.5, 16813, 16651.5, 15432, 14655
), sd_fecha = c(266.25, 235.5, 131.5, 327.5, 210.25, 267.75,
267, 262, 239.25, 304, 283.75, 189.75, 266.75, 174, 294.75,
278.5, 331, 266.75, 204.75, 215.5, 196, 285.25, 196, 288.5,
250.25, 277, 63.75, 101.75, 100.75, 168, 337.5, 136.25, 212.75,
183.25, 199.25, 206.5, 193, 264.75, 312.25, 235.5, 299.25,
238.5, 312.5)), row.names = c(NA, -43L), class = c("tbl_df",
"tbl", "data.frame"))
This dataset is composed of 3 columns:
FIGURE: categorical variablemedia_fecha: mean value for that element/row of the dataset.sd_fecha: standard deviation for that element/row of the dataset.
The category XLIV in FIGURE is composed of three rows or elements.
I am interested in plotting this by using ggplot2.
- For example, illustrate three normal distributions of
XLIVby using their corresponding means and deviations. And also, highlight the overlapping area.
How could I do it?
UPDATE
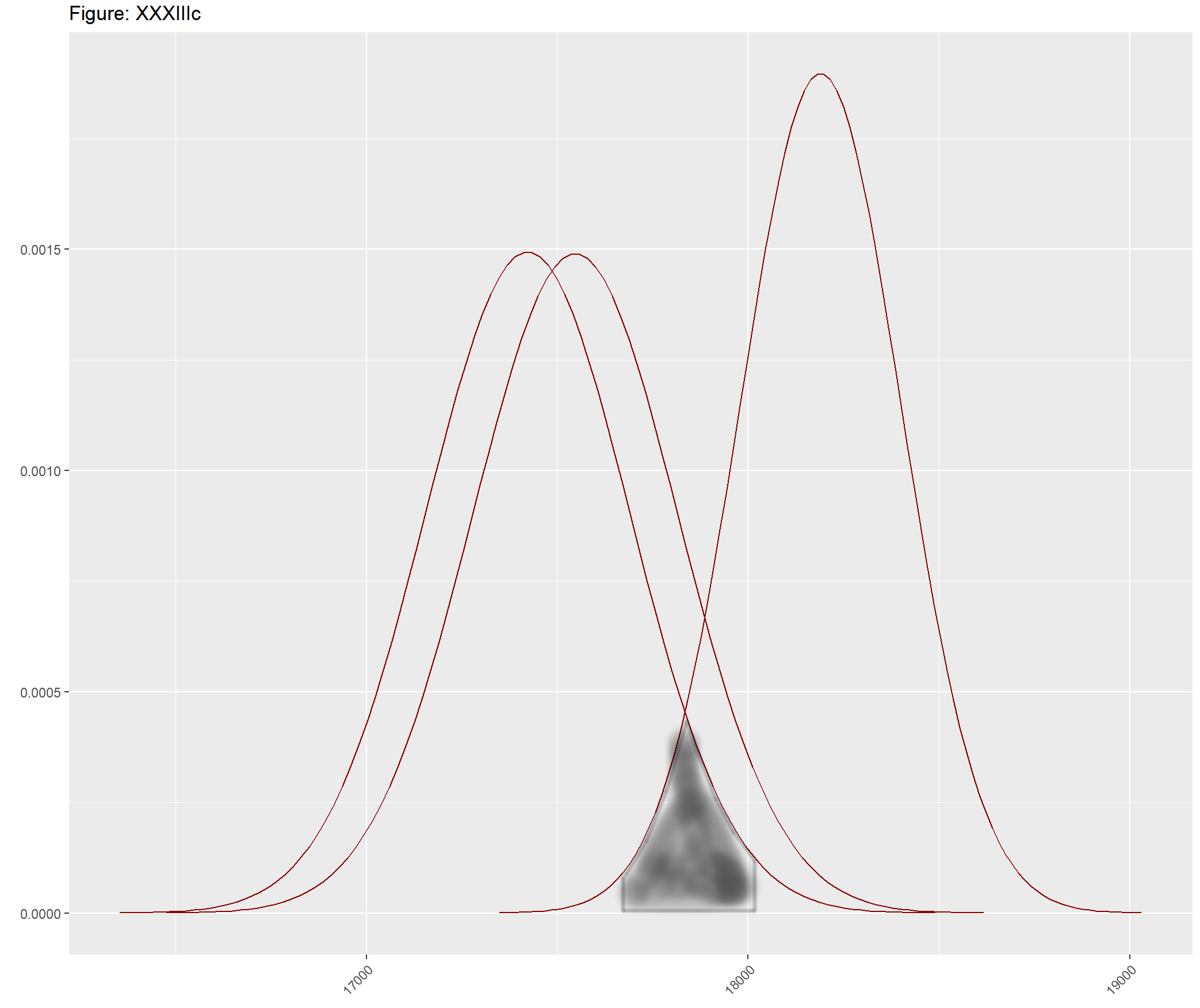
I would like to give a color to the overlapping area between all the density functions taking into account their corresponding 2 sigma limit. Something similar to this example of XXXIIIc:
CodePudding user response:
You could group your data row-wise, summarize with 100 x and y values from, say, 4 sd below to 4 sd above the means, then plot with plain old geom_line.
If you want to highlight the areas where all the curves overlap (within 2 sd of each mean), you can find the x values that lie within that range for all curves, then mark the highest y values where this is true for filling.
We can wrap all this in a function for ease of use and consistency:
library(tidyverse)
plot_norms <- function(data, fig, ...) {
x %>%
filter(FIGURE == fig) %>%
mutate(min_range = min(media_fecha - 4 * sd_fecha),
max_range = max(media_fecha 4 * sd_fecha)) %>%
mutate(group = row_number()) %>%
rowwise() %>%
summarise(x = seq(min_range, max_range, length.out = 500),
y = dnorm(x, media_fecha, sd_fecha),
is_2d = x > media_fecha - 2 * sd_fecha &
x < media_fecha 2 * sd_fecha,
FIGURE = FIGURE, group = group) %>%
group_by(x) %>%
mutate(fill_me = all(is_2d) & rank(y) == max(rank(y))) %>%
ggplot(aes(x, y))
geom_area(data = . %>% filter(fill_me), ..., position = 'identity')
geom_line(aes(group = group))
ggtitle(paste("Normal distributions, figure", fig))
theme_minimal(base_size = 16)
}
So now you can do:
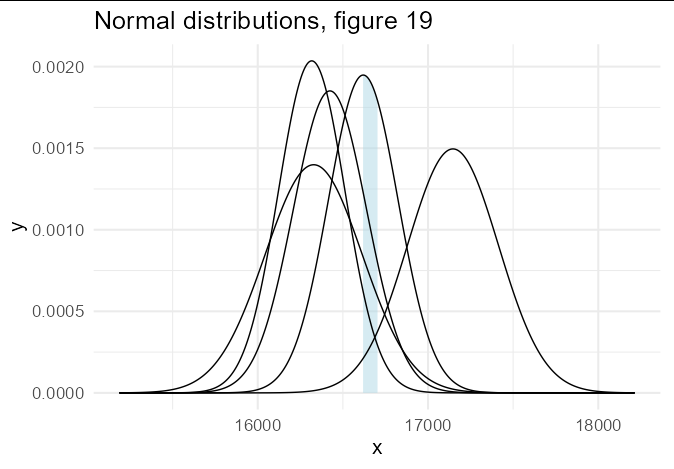
plot_norms(x, "19", fill = 'lightblue', alpha = 0.5)
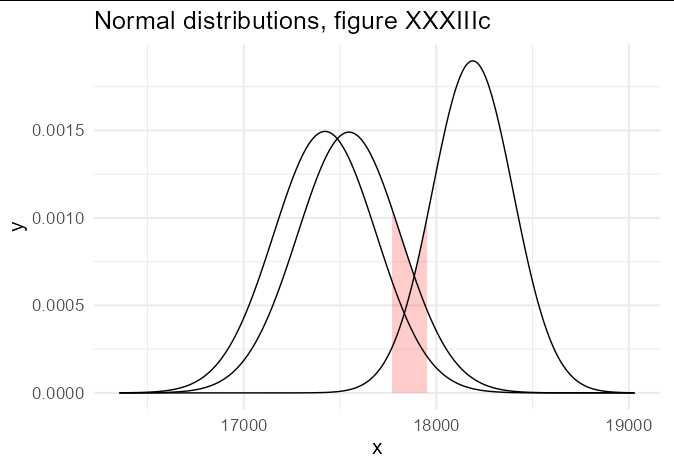
plot_norms(x, "XXXIIIc", fill = 'red', alpha = 0.2)
Created on 2022-11-12 with reprex v2.0.2