let's assume I have big data frame X (around 500,000 rows), and small data frame y (around 3000 rows). I need to do join between those df's, and then I need to filter on the result df. I recently realized I can do the filtering on X and that will give me the same result as filtering on the result joined df. the filtering ensures me really small df.
This code is already in use. my question is: Does spark smart enough to do the filter before the join operation and to "ease" the join? Or maybe this is just small improvement.
CodePudding user response:
It may depend on your source and usage but in general Spark has optimization rules which are pushing filter down to source
You can check in SparkUI if this data are read right now on your production code
Here i have small example on my databricks cluster:
import org.apache.spark.sql.functions._
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
spark.conf.set("spark.sql.adaptive.enabled", false)
val input = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/shared_uploads/***@gmail.com/city_temperature.csv")
val dataForInput2 = Seq(("Algeria", "3"),("Germany", "3"), ("France", "5"), ("Poland", "7"), ("test55", "86"))
val input2 = dataForInput2.toDF("Country", "Value")
val joinedDfs = input.join(input2, Seq("Country"))
val finalResult = joinedDfs.filter(input("Country") === "Poland")
finalResult.show
In query plan you can see that filter was pushed and done before join:
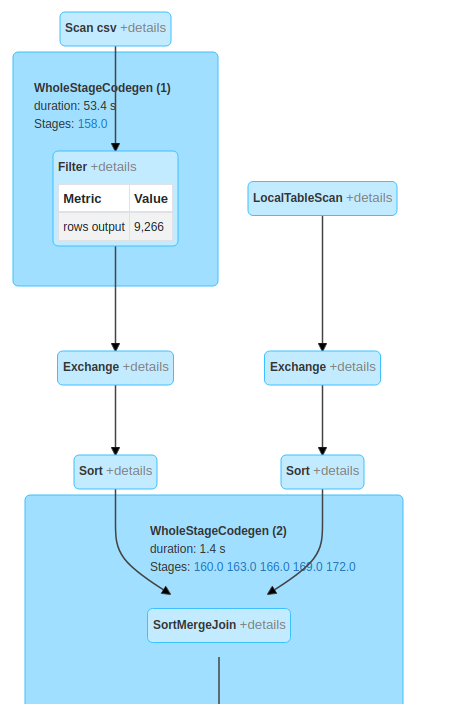
CodePudding user response:
This code is already in use. my question is: Does spark smart enough to do the filter before the join operation and to "ease" the join? Or maybe this is just small improvement.
Yes, what you have observed is called predicate pushdown or filter pushdown. The support depends on the data source, but in general predicate pushdown exploits the data source to do the filtering for it, which saves time and compute power. More on this - https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-Optimizer-PushDownPredicate.html