I have one column to compare with other 100 columns. The columns I need to compare are all DATETIME The problem statement is as follows:
- If the date in the "UTIL_DATE" is greater than equal to the date in other columns, substitute that row's value to 1
- Else, 0
I have attached an example image below for the reference.
For example: Since UTIL_DATE "31-12-2021" is greater than "23-09-2021", then we change the row value in column "Col3" to 1. Since there is NaT in Col1, Col2 (and so one), those specific cannot be compared with UTIL_DATE. Hence, 0.
And the same thing iterate over for all the other rows
CURRENTLY
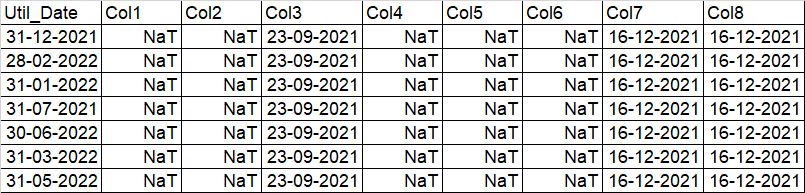
EXPECTED
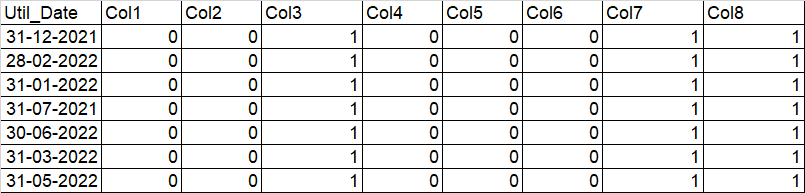
I have tried a try-except loop. However, it is taking more than 1 hour 30 mins. I need to improve the performance.
Attached the code snippet for your reference:
for idx, row in df.iterrows(): # row is each row in df and idx is the index for each row
for i in format_cols: # format_cols is the list of columns to be compared with the UTIL_DATE column
ifor_val = 0 # taking ifor_val as 0 by default
try:
if (pd.to_datetime(row["Util_Date"]) >= pd.to_datetime(row[i])):
ifor_val = 1 # if Util_Date >= column "i" date, then map it to 1. Else 0
except:
ifor_val = 0
df.loc[idx,i]=ifor_val
CodePudding user response:
can you try this:
df=df.set_index('UTIL_DATE')
df=df.ge(df.index, axis=0)
df=df.replace({True:1,False:0})