I am using Conv-LSTM for training, and the input features have been proven to be effective in some papers, and I can use CNN FC networks to extract features and classify them. I change the task to regression here, and I can also achieve model convergence with Conv FC. Later, I tried to use Conv-LSTM for processing to consider the timing characteristics of the corresponding data. Specifically: return the output of the current moment based on multiple historical inputs and the input of the current moment. The Conv-LSTM code I used: 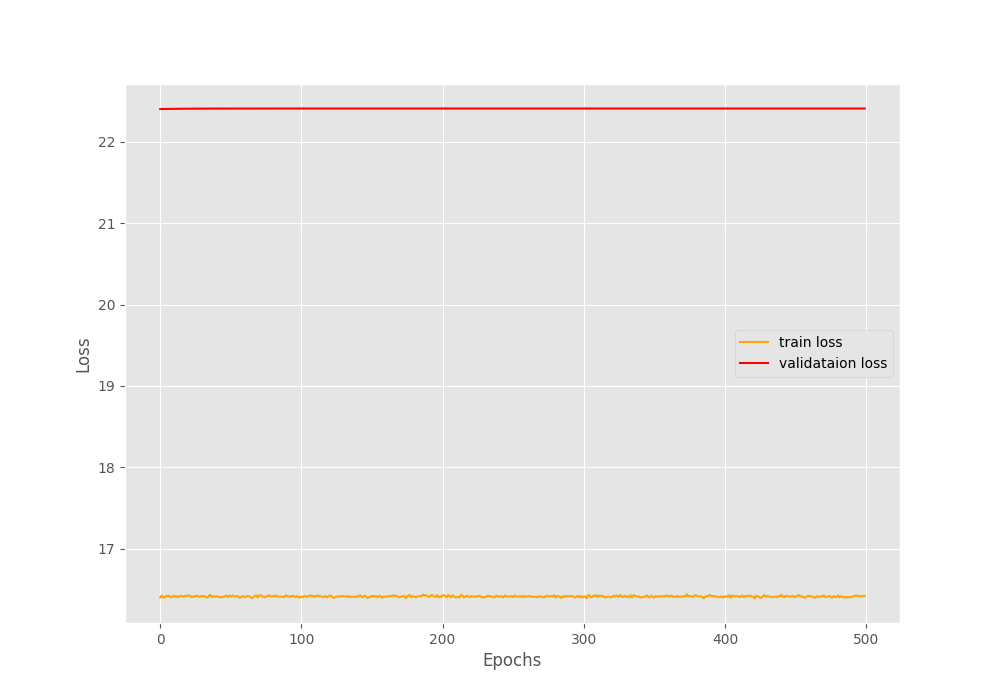
Example loss value:
Epoch:1/500 AVG Training Loss:16.40108 AVG Valid Loss:22.40100
Best validation loss: 22.400997797648113
Saving best model for epoch 1
Epoch:2/500 AVG Training Loss:16.42522 AVG Valid Loss:22.40100
Epoch:3/500 AVG Training Loss:16.40599 AVG Valid Loss:22.40100
Epoch:4/500 AVG Training Loss:16.40175 AVG Valid Loss:22.40100
Epoch:5/500 AVG Training Loss:16.42198 AVG Valid Loss:22.40101
Epoch:6/500 AVG Training Loss:16.41907 AVG Valid Loss:22.40101
Epoch:7/500 AVG Training Loss:16.42531 AVG Valid Loss:22.40101
My attempt:
- Adjust the data set to only a few samples, verify that it can be overfitted, and the network code should be fine.
- Adjusting the learning rate, I tried 1e-3, 1e-4, 1e-5 and 1e-6, but the loss curve is still flat as before, and even the value of the loss curve has not changed much.
- Replace the optimizer with SGD, and the training result is also the above problem.
Because my data is wireless data (I-Q), neither CV nor NLP input type, here are some questions to ask about deep learning training.
CodePudding user response:
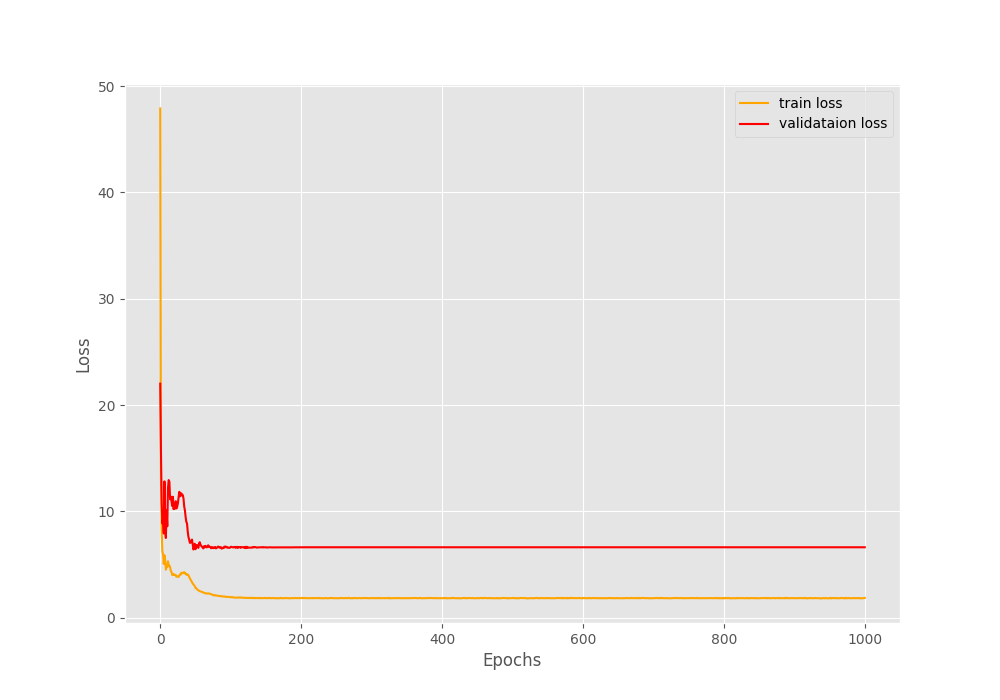
After some testing, I finally found that my initial learning rate was too small. According to my previous single-point data training, the learning rate of 1e-3 is large enough, so here is preconceived, and it is adjusted from 1e-3 to a small tune, but in fact, the learning rate of 1e-3 is too small, resulting in the network not learning at all. Later, the learning rate was adjusted to 1e-2, and both the train loss and validate loss of the network achieved rapid decline (And the optimizer is Adam). When adjusting the learning rate later, you can start from 1 to the minor, do not preconceive.