I have a database with over 30,000,000 entries. When performing queries (including an ORDER BY clause) on a text field, the = operator results in relatively fast results. However we have noticed that when using the LIKE operator, the query becomes remarkably slow, taking minutes to complete. For example:
SELECT * FROM work_item_summary WHERE manager LIKE '%manager' ORDER BY created;
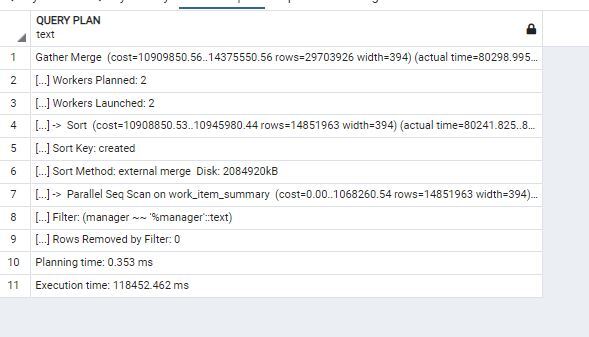
Creating indices on the keywords being searched will of course greatly speed up the query. The problem is we must support queries on any arbitrary pattern, and on any column, making this solution not viable.
My questions are:
- Why are
LIKEqueries this much slower than=queries? - Is there any other way these generic queries can be optimized, or is about as good as one can get for a database with so many entries?
CodePudding user response:
Your query plan shows a sequential scan, which is slow for big tables, and also not surprising since your LIKE pattern has a leading wildcard that cannot be supported with a plain B-tree index.
You need to add index support. Either a trigram GIN index to support any and all patterns, or a COLLATE "C" B-tree expression index on the reversed string to specifically target leading wildcards.
See:
- PostgreSQL LIKE query performance variations
- How to index a column for leading wildcard search and check progress?
CodePudding user response:
I tried GIN indexing on the text searching column "manager" however this query:
SELECT id FROM work_item_summary WHERE manager LIKE '%manager';
refuse to use the GIN index with EXPLAIN
"Seq Scan on work_item_summary (cost=0.00..349973.00 rows=8880000 width=1070) (actual time=0.599..3239.596 rows=8880000 loops=1)"
" Filter: ((manager)::text ~~ '%manager'::text)"
"Planning time: 0.208 ms"
"Execution time: 3459.981 ms"
On the other hand tried:
SELECT * FROM work_item_summary WHERE manager LIKE '%manager' ORDER BY created;
and it took about 1 minute which uses the B-tree index on the timestamp column 'created'
with EXPLAIN
"Index Scan using idx_work_item_summary_created on work_item_summary (cost=0.44..529368.44 rows=8880000 width=1070) (actual time=0.829..8105.519 rows=8880000 loops=1)"
" Filter: ((manager)::text ~~ '%manager'::text)"
"Planning time: 1.061 ms"
"Execution time: 8358.714 ms"
does indexing with B-tree on timestamp column and GIN indexing on text searching column hurt the performance? perhaps its because of combining two indexing type?
Is execution time of 30 seconds to 1 minute reasonable for table of 30 million entries in POSTGRES? can it be speedup to milliseconds?