I'm trying to create a combination of concentrations of two chemicals for an experiment. Since I want to see which combination of both is the best I want to create an overview how much I need to add of each at a given concentration. So far I managed to create two pivot_tables/dataframes of each but Im somehow don't get them to merge into one.
So I've tried this approach so far:
import numpy as np
import pandas as pd
array_CinA = np.array([0,125,250,500,1000])
array_Aceto = np.array([0,100,200,400,800])
vol_cina = [0, 5, 10, 20, 40]
vol_as = [0, 2, 4,8,16]
array = np.array(np.meshgrid(array_CinA,array_Aceto)).T.reshape(-1,2)
df = pd.DataFrame({"CinnamonicAcid":array_CinA,
"Acetosyringone":array_Aceto,
"VolCinA": vol_cina,
"VolAS": vol_as})
pivtab = df.pivot_table(index="CinnamonicAcid", columns="Acetosyringone", values=["VolCinA", "VolAS"])
#pivtab.to_excel
print(pivtab)
Which gives me the following output:
VolAS VolCinA
Acetosyringone 0 100 200 400 800 0 100 200 400 800
CinnamonicAcid
0 0.0 NaN NaN NaN NaN 0.0 NaN NaN NaN NaN
125 NaN 2.0 NaN NaN NaN NaN 5.0 NaN NaN NaN
250 NaN NaN 4.0 NaN NaN NaN NaN 10.0 NaN NaN
500 NaN NaN NaN 8.0 NaN NaN NaN NaN 20.0 NaN
1000 NaN NaN NaN NaN 16.0 NaN NaN NaN NaN 40.0
My desired output would be something like this:
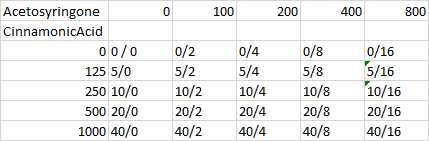
CodePudding user response:
The below code should be what you are after.
I am using product function from intertools library to create the full data. Then I am just converting to string type so that numpy doesn't get confused and I reshape it. Finally I am producing a dataframe providing index names and column names.
import numpy as np
import pandas as pd
from itertools import product
array_CinA = np.array([0, 125, 250, 500, 1000])
array_Aceto = np.array([0, 100, 200, 400, 800])
vol_cina = [0, 5, 10, 20, 40]
vol_as = [0, 2, 4, 8, 16]
# creating full data
my_product = list(product(vol_cina, vol_as))
# converting to str
my_product_str = [str(a) for a in my_product]
# converting to np array
my_product_str_np = np.array(my_product_str)
# reshaping
my_product_str_np = my_product_str_np.reshape(len(vol_cina), len(vol_as))
# producing final data
df = pd.DataFrame(my_product_str_np, index=array_CinA, columns=array_Aceto)
df.index.name="CinnamonicAcid"
df.columns.name="Acetosyringone"
print(df)
CodePudding user response:
Use numpy.broadcast_to for new 2d arrays and divide them, then pass to DataFrame constructor:
array_CinA = np.array([0,125,250,500,1000])
array_Aceto = np.array([0,100,200,400,800])
vol_cina = [0, 5, 10, 20, 40]
vol_as = [0, 2, 4,8,16]
shape = (len(array_Aceto), len(array_CinA))
arr = np.core.defchararray.add(np.array(vol_cina).astype(str), '/')[:, None]
a1 = np.broadcast_to(arr, shape)
a2 = np.broadcast_to(np.array(vol_as).astype(str), shape)
df = (pd.DataFrame(np.core.defchararray.add(a1, a2), index=array_CinA, columns=array_Aceto))
print (df)
0 100 200 400 800
0 0/0 0/2 0/4 0/8 0/16
125 5/0 5/2 5/4 5/8 5/16
250 10/0 10/2 10/4 10/8 10/16
500 20/0 20/2 20/4 20/8 20/16
1000 40/0 40/2 40/4 40/8 40/16