I converted the following dictionary to a dataframe:
dic = {'US':{'Traffic':{'new':1415, 'repeat':670}, 'Sales':{'new':67068, 'repeat':105677}},
'UK': {'Traffic':{'new':230, 'repeat':156}, 'Sales':{'new':4568, 'repeat':10738}}}
d1 = defaultdict(dict)
for k, v in dic.items():
for k1, v1 in v.items():
for k2, v2 in v1.items():
d1[(k, k2)].update({k1: v2})
df.insert(loc=2, column=' ', value=None)
df.insert(loc=0, column='Mode', value='Website')
df.columns = df.columns.rename("Metric", level=1)
The dataframe currently looks like:
How do I move the column header - Mode to the following row?
To get an output of this sort: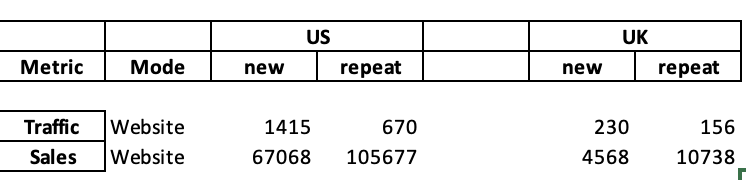
CodePudding user response:
Change this:
df.insert(loc=0, column='Mode', value='Website')
to this:
df.insert(loc=0, column=('', 'Mode'), value='Website')
then your full code looks like this:
import pandas as pd
from collections import defaultdict
dic = {'US':{'Traffic':{'new':1415, 'repeat':670}, 'Sales':{'new':67068, 'repeat':105677}},
'UK': {'Traffic':{'new':230, 'repeat':156}, 'Sales':{'new':4568, 'repeat':10738}}}
d1 = defaultdict(dict)
for k, v in dic.items():
for k1, v1 in v.items():
for k2, v2 in v1.items():
d1[(k, k2)].update({k1: v2})
df = pd.DataFrame.from_dict(d1)
df.insert(loc=0, column=('', 'Mode'), value='Website')
and this is your df
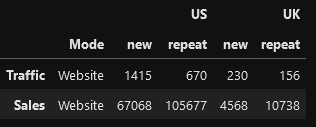
Rinse and repeat with your empty column between US and UK.
(though, admittedly, this looks like a strange way of handling stuff)