I have a dataframe df where one column 'Images' contains a bunch of HTML strings in each row from which I would like to extract URLs, that have a specific Start and End characters. Ideally they would then be turned into columns for each URL extracted.
df example:
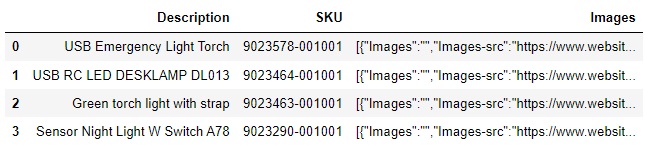
df = pd.DataFrame({
'Description': ['USB Emergency Light Torch', 'USB RC LED DESKLAMP DL013', 'Green torch light with strap', 'Sensor Night Light W Switch A78'],
'SKU': ['9023578-001001', '9023464-001001', '9023463-001001', '9023290-001001'],
'Images': ['[{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023578-temp.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023578-3.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023578.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023578-temp.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023578.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023578-1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023578-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023578-3.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/4c186adb30ce12db4dc6d068ea20241d/9/0/9023578-temp.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/wysiwyg/mageplus/_images/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://image.useinsider.com/default/action-builder/instant-purchase.png"}]',
'[{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023464-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023464-1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023464.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023464-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023464.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023464-1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/4c186adb30ce12db4dc6d068ea20241d/9/0/9023464-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/wysiwyg/mageplus/_images/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://image.useinsider.com/default/action-builder/instant-purchase.png"}]',
'[{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023463-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023463-1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023463.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023463-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023463.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023463-1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/4c186adb30ce12db4dc6d068ea20241d/9/0/9023463-2.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/wysiwyg/mageplus/_images/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://image.useinsider.com/default/action-builder/instant-purchase.png"}]',
'[{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/logo/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023290-2_1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023290.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/9/0/9023290-1_1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023290-2_1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023290-1_1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/f0229e02574c793c147c08297c074a46/9/0/9023290.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/catalog/product/cache/4c186adb30ce12db4dc6d068ea20241d/9/0/9023290-2_1.jpg"},{"Images":"","Images-src":"https://www.website.com.my/media/wysiwyg/mageplus/_images/stores/3/logo-b2b_1_-min.png"},{"Images":"","Images-src":"https://image.useinsider.com/default/action-builder/instant-purchase.png"}]']
})
Which looks like this:
Start: https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d
End: .jpg
The other URLs and text can be ignored.
Desired Output (one URL per column, added to the end of the df; there might be more than 3 results, so the number of columns added is variable):
https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/8/9/8993791-temp.jpg
https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/8/9/8993791-3.jpg
https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/8/9/8993791.jpg
Here's an image example of the desired output in case:

So far I tried this code below (it only extracts to a single cell with "," as a joiner, haven't figured the column splitting yet) but the output is a seemingly empty cell with just '' contained within:
df['img_lines'] = df['Images'].str.findall('^https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d.*\.jpg$').str.join(",")
CodePudding user response:
It looks like you are indexing wrong column of the DataFrame. Instead of df['Images'], you should do - df['Images-src'], as the links are in the latter column.
df['Images-src'].str.findall('^https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d.*\.jpg$').str.join(",")
EDIT:
Might not be the most efficient way. But, one thing you can do is convert the HTML string to python object using json.loads, and then create a new DataFrame and then filter the results.
import json #Importing json module
for i in df['Images']: #Loops through the string
df1 = pd.DataFrame(json.loads(i)) #Creates a new DataFrame with prev string as python object
print(df1['Images-src'].str.findall('^https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d.*\.jpg$').str.join(","))
O/P:
0
1
2 https://www.website.com.my/media/catalog/produ...
3 https://www.website.com.my/media/catalog/produ...
4 https://www.website.com.my/media/catalog/produ...
5
6
7
8
9
10
11
12
Name: Images-src, dtype: object
If you want to print like your desired output:
a = df1['Images-src'].str.findall('^https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d.*\.jpg$').str.join(",")
for i in a:
if i != '':
print(i)
O/P:
https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/8/9/8993791-temp.jpg
https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/8/9/8993791-3.jpg
https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d/8/9/8993791.jpg
I'll leave the logical part to you for implementing it.
CodePudding user response:
Example
s1 = pd.Series(['aaa123.jpg', 'bca234.jpg', 'aaa425.gif', 'aaa234.jpg'])
s1
0 aaa123.jpg
1 bca234.jpg
2 aaa425.gif
3 aaa234.jpg
dtype: object
Code
if you want extract from 'aa' to '.jpg'
s1.str.extract('(aa. .jpg)').dropna()[0]
result:
0 aaa123.jpg
3 aaa234.jpg
Name: 0, dtype: object
in your example
start = 'https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d'
pat = '({}[^ ] .jpg)'.format(start)
result = df['Images'].str.split('Images-src').explode().str.extract(pat).dropna()
result:
0
0 https://www.website.com.my/media/catalog/produ...
0 https://www.website.com.my/media/catalog/produ...
0 https://www.website.com.my/media/catalog/produ...
1 https://www.website.com.my/media/catalog/produ...
1 https://www.website.com.my/media/catalog/produ...
1 https://www.website.com.my/media/catalog/produ...
2 https://www.website.com.my/media/catalog/produ...
2 https://www.website.com.my/media/catalog/produ...
2 https://www.website.com.my/media/catalog/produ...
3 https://www.website.com.my/media/catalog/produ...
3 https://www.website.com.my/media/catalog/produ...
3 https://www.website.com.my/media/catalog/produ...
make result to dataframe
result.groupby(level=0)[0].agg(list).apply(lambda x: pd.Series(x))
output:
0 1 2
0 https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ...
1 https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ...
2 https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ...
3 https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ... https://www.website.com.my/media/catalog/produ...
concat output to your df and rename
CodePudding user response:
This can be done without regex using native string methods along with other built-in python modules: json and itemgetter (this one's not necessary but useful for convenience). In short, Images column contains json objects, so convert each item to a python list and simply search for the relevant URLs in it.
json.loads call creates a list of dictionaries and since you only care about the URLs under the 'Images-src' key, get them using itemgetter() first. Then among these URLs, see filter the ones that starts and ends with the specific pattern you want.
import json
from operator import itemgetter
df[['URL1','URL2','URL3']] = [[url for url in map(itemgetter('Images-src'), lst) if url.startswith('https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d') and url.endswith('.jpg')] for lst in df['Images'].map(json.loads)]
If you insist on regex, re.match might be useful in the last step. The idea is to see if a string starts with the pattern you want; has whatever and ends with .jpg:
import re
df[['URL1','URL2','URL3']] = [[url for url in map(itemgetter('Images-src'), lst) if re.match(r'https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d.*\.jpg$', url)] for lst in df['Images'].map(json.loads)]

If there are variable number of columns, it is best to cast to a dataframe first and join() to df later to avoid a ValueError (see this post):
df = df.join(pd.DataFrame([[url for url in map(itemgetter('Images-src'), lst) if url.startswith('https://www.website.com.my/media/catalog/product/cache/3f354f4955006fba9bb013076742094d') and url.endswith('.jpg')] for lst in df['Images'].map(json.loads)]).add_prefix('URL'))