I tried reading data from the GCS bucket on pyspark using the following code:
df_business = spark.read.json("gs://[bucket_name]/[filename].json")
I want to do the same using the R kernel on the Jupyter lab and run a regression model.

Any help would be appreciated...
CodePudding user response:
You can follow the following steps:
Configure googleCloudStorageR library with proper authentication with service account.
options(googleAuthR.scopes.selected="https://www.googleapis.com/auth/cloud-platform")library(googleCloudStorageR)gcs_auth(email="[email protected]")provide project,bucket, object name you want to read
proj <- "project1"bucket_name <- "load1"gfs_tmp_file <- "bqloading.csv"gogleCloudStorageR::gcs_global_bucket(bucket_name)gfs_file <- googleCloudStorageR::gcs_get_object(gfs_tmp_file)gfs_file
Output:
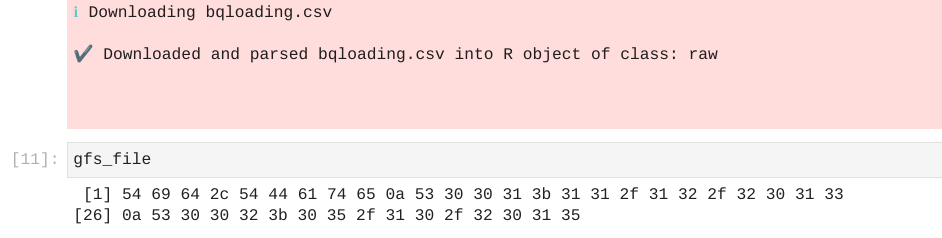
- If required, you can convert this raw data into R data frame following this thread.