I have the following dataset:
id test date
1 A 2000-01-01
1 B 2000-01-01
1 C 2000-01-08
2 A 2000-01-01
2 A 2000-01-01
2 B 2000-01-08
3 A 2000-01-01
3 C 2000-01-01
3 B 2000-01-08
4 A 2000-01-01
4 B 2000-01-01
4 C 2000-01-01
5 A 2000-01-01
5 B 2000-01-01
5 C 2000-01-01
I would love to create a matrix figure with the count of how many individuals got a test taken on the same day.
For example:

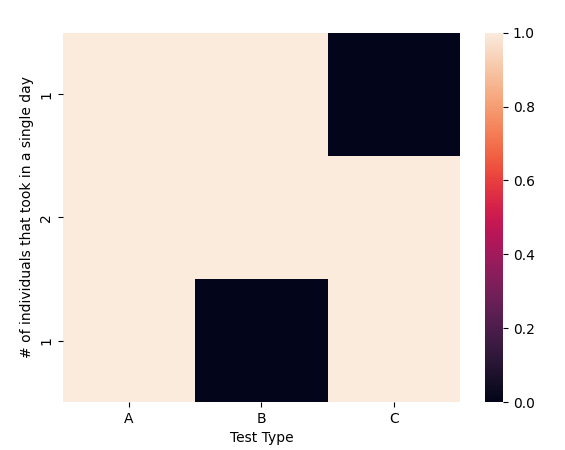
Since we can see that 1 time (for one individual, id=1) test A and B were taken on the day; also for one individual (id = 3) test A and B were taken on the same day; and for two individuals (id=4 and 5) the three tests were taken on the same day.
So far I am doing the following:
df_tests = df.groupby(['id', 'date']).value_counts().reset_index(name='count')
df_tests_unique = df_tests[df_tests_re.duplicated(subset=['id','date'], keep=False)]
df_tests_unique = df_tests_unique[["id", "date", "test"]]
So the only thing left is to count the number of times the different tests ocur within the same date
CodePudding user response:
Thanks for the fun exercise :) Given below is a possible solution. I created a numpy array and plotted it using seaborn. Note that it's quite hardcoded for the case where there is only A, B, C but I'm sure you will be able to generalize that. Also, the default color scheme of seaborn brings opposite colors than what you intended but that's easily fixable as well. Hope I helped!
This is the resulting plot from the script:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.DataFrame({
'id': [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5],
'test': ['A', 'B', 'C', 'A', 'A', 'B', 'A', 'C', 'B', 'A', 'B', 'C', 'A', 'B', 'C'],
'date': ['2000-01-01', '2000-01-01', '2000-01-08', '2000-01-01', '2000-01-01', '2000-01-08', '2000-01-01', '2000-01-01', '2000-01-08', '2000-01-01', '2000-01-01', '2000-01-01', '2000-01-01', '2000-01-01', '2000-01-01']
})
df_tests = df.groupby(['id', 'date']).value_counts().reset_index(name='count')
df_test_with_patterns = (df_tests[df_tests.duplicated(subset=['id', 'date'], keep=False)]
.groupby(['id', 'date'])
.agg({'test': 'sum'})
.reset_index().groupby('test').count().reset_index()
.assign(pattern=lambda df: df.test.apply(lambda tst: [1 if x in tst else 0 for x in ['A', 'B', 'C']]))
)
pattern_mat = np.vstack(df_test_with_patterns.pattern.values.tolist())
ax = sns.heatmap(pattern_mat, xticklabels=['A', 'B', 'C'], yticklabels=df_test_with_patterns.id.values)
ax.set(xlabel='Test Type', ylabel='# of individuals that took in a single day')
plt.show()
print
CodePudding user response:
Building on Erap answer, this works too, maybe slightly faster:
out = pd.get_dummies(df.set_index(['date', 'id'], drop=True).sort_index()).groupby(level=[0,1]).sum()
and then iterate through the different dates to get the different charts
for i in out.index.levels[0]:
d = out.loc[i]
plt.figure()
plt.title(f'test for date {i}')
sns.heatmap(d.gt(0))