I'm very new to web scraping and have run into an issue where I'm trying to scrape the World Football Elo Ratings webpage (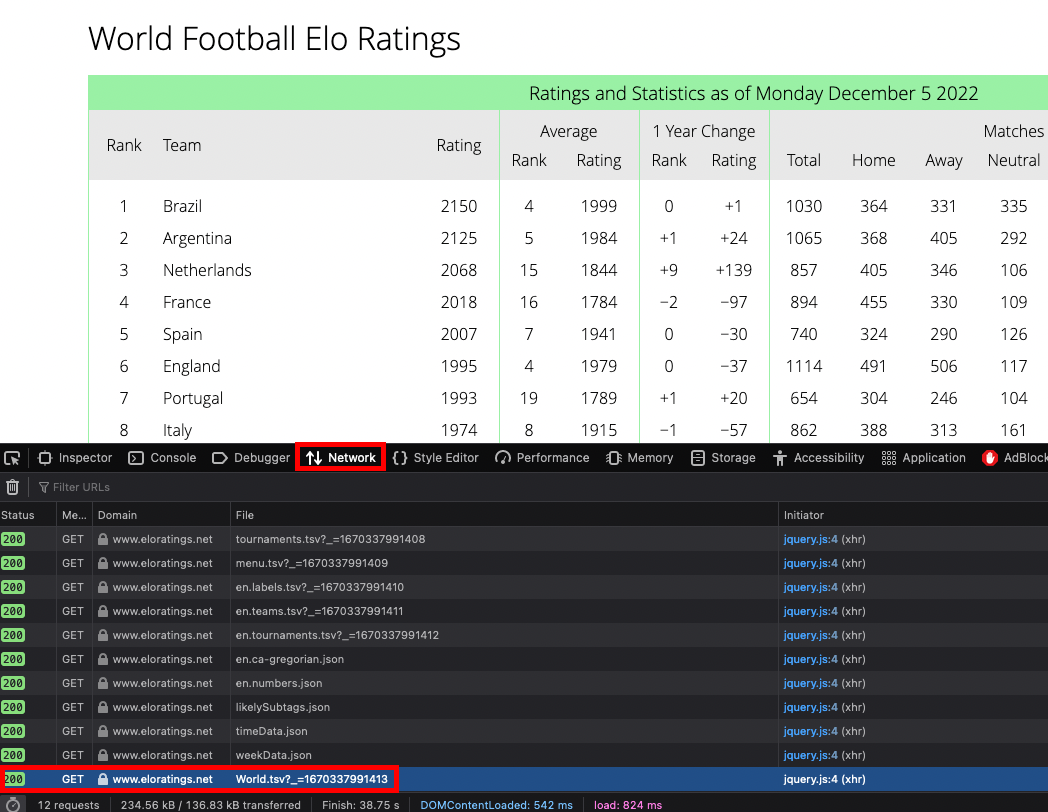
You can read a .tsv into a dataframe directly from the URL:
import pandas as pd
df = pd.read_csv('https://www.eloratings.net/World.tsv?_=1670337991413',sep = '\t')
print(df)
CodePudding user response:
I am relatively new to Stack Overflow, and in fact you are the first question I am going to try to offer any advice to!
I am not too sure what you are looking to do, ie: are you trying to get each country and their stats? Or are you simply looking for the order of rankings?
I have in the past done something similar using Selenium.
I loaded up the webpage you are looking to scrape and tried to figure out how I would do it.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
import time
fireFoxOptions = Options()
fireFoxOptions.headless = True
driver = webdriver.Firefox(options=fireFoxOptions)
driver.get("https://www.eloratings.net/")
original_window = driver.current_window_handle
wait = WebDriverWait(driver, 10)
time.sleep(10)
num = 1
stats = []
for i in range(1,240):
div_name = f"div.ui-widget-content:nth-child({num})"
element = driver.find_elements(By.CSS_SELECTOR, div_name)
num = num 1
stats.append(element)
print(stats)
This little bit of code will go in headless mode (no gui) of firefox and get all the div elements that match the css_selector. Unfortunately their wasn't a common CSS_SELECTOR name between all the elements yet they did have a pattern of just changing the number in the (). So just using a simple four loop we can get all of them. From here if you wanted to get each link for instance you would do something like:
for stat in stats:
link = stats.get_attribute("href")
Then you could iterate through those links and follow them to the their teams page.
I hope this helps!
Let me know if you have any questions or advice.