I am trying to create a PySpark data frame with a single column that contains the date range, but I keep getting this error. I also tried converting it to an int, but I am not sure if you are even supposed to do that.
# Gets an existing SparkSession or, if there is no existing one, creates a new one
spark = SparkSession.builder.appName('pyspark-shellTest2').getOrCreate()
from pyspark.sql.functions import col, to_date, asc
from pyspark.sql.types import TimestampType
import datetime
# Start and end dates for the date range
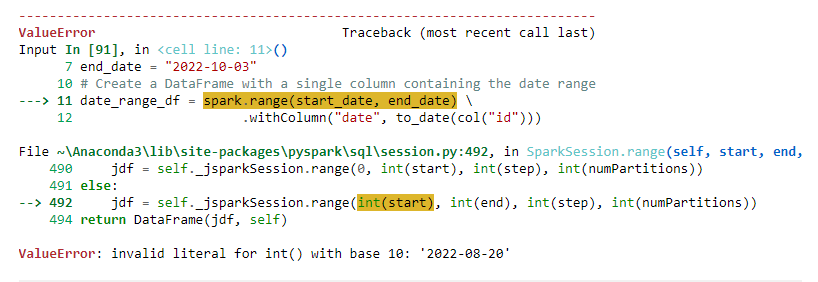
start_date = "2022-08-20"
end_date = "2022-10-03"
# Create a DataFrame with a single column containing the date range
date_range_df = spark.range(start_date, end_date) \
.withColumn("date", to_date(col("id")))
Error:
CodePudding user response:
you can use the sequence sql function to create an array of dates using the start and end. this array can be exploded to get new rows.
see example below
spark.sparkContext.parallelize([(start_date, end_date)]). \
toDF(['start', 'end']). \
withColumn('start', func.to_date('start')). \
withColumn('end', func.to_date('end')). \
withColumn('date_seq', func.expr('sequence(start, end, interval 1 day)')). \
select(func.explode('date_seq').alias('date')). \
show(10)
# ----------
# | date|
# ----------
# |2022-08-20|
# |2022-08-21|
# |2022-08-22|
# |2022-08-23|
# |2022-08-24|
# |2022-08-25|
# |2022-08-26|
# |2022-08-27|
# |2022-08-28|
# |2022-08-29|
# ----------
# only showing top 10 rows