I have a task to compute Pi with following formula:
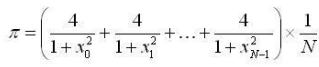
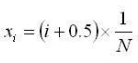
(i is in range from 0 to N, N = 10^8)
Computation should be completed in multiple threads with following requirement: each thread receives only a small fixed amount of computations to complete (in my case - 40 sum members at a time), and there should be a "Task pool" which gives new set of computations into a thread when it reports completion of previous set of operations given to it. Before a thread receives new task, it should wait. All of this should be done with WinAPI.
My solution is this class:
#include "ThreadManager.h"
#include <string>
HANDLE ThreadManager::mutex = (CreateMutexA(nullptr, true, "m"));
ThreadManager::ThreadManager(size_t threadCount)
{
threads.reserve(threadCount);
for (int i = 0; i < threadCount; i )
{
threadInfo.push_back(new ThreadStruct(i * OP_COUNT));
HANDLE event = CreateEventA(nullptr, false, true, std::to_string(i).c_str());
if (event)
{
threadEvents.push_back(event);
DuplicateHandle(GetCurrentProcess(), event, GetCurrentProcess(),
&(threadInfo[i]->threadEvent), 0, false, DUPLICATE_SAME_ACCESS);
}
else std::cout << "Unknown error: " << GetLastError() << std::endl;
HANDLE thread = CreateThread(nullptr, 0,
reinterpret_cast<LPTHREAD_START_ROUTINE>(&ThreadManager::threadFunc),
threadInfo[i],
CREATE_SUSPENDED, nullptr);
if (thread) threads.push_back(thread);
else std::cout << "Unknown error: " << GetLastError() << std::endl;
}
}
double ThreadManager::run()
{
size_t operations_done = threads.size() * OP_COUNT;
for (HANDLE t : threads) ResumeThread(t);
DWORD index;
Sleep(10);
while (operations_done < ThreadManager::N)
{
ReleaseMutex(ThreadManager::mutex);
index = WaitForMultipleObjects(this->threadEvents.size(), this->threadEvents.data(), false, 10000);
WaitForSingleObject(ThreadManager::mutex, 1000);
threadInfo[index] -> operationIndex = operations_done OP_COUNT;
SetEvent(threadEvents[index]);
//std::cout << "Operations completed: " << operations_done << "/1000" << std::endl;
operations_done = OP_COUNT;
}
long double res_pi = 0;
for (auto&& ts: this->threadInfo)
{
res_pi = ts->pi;
ts->operationIndex = N;
}
res_pi /= N;
WaitForMultipleObjects(this->threads.size(), this->threads.data(), true, 10000);
std::cout.precision(10);
std::cout << "Pi value for " << threads.size() << " threads: " << res_pi;
threads.clear();
return 0;
}
ThreadManager::~ThreadManager()
{
if (!threads.empty())
for (HANDLE t: threads)
{
TerminateThread(t, -1);
CloseHandle(t);
}
std::destroy(threadInfo.begin(), threadInfo.end());
}
long double ThreadManager::calc(size_t startIndex)
{
long double xi = 0;
long double pi = 0;
for (size_t i = startIndex; i < startIndex OP_COUNT; i )
{
const long double ld_i = i;
const long double half = 0.5f;
xi = (ld_i half) * (1.0 / N);
pi = ((4.0 / (1.0 xi * xi)));
}
return pi;
}
DWORD WINAPI ThreadManager::threadFunc(ThreadStruct *ts)
{
while (ts->operationIndex < N)
{
WaitForSingleObject(ts->threadEvent, 1000);
ts->pi = calc(ts->operationIndex);
WaitForSingleObject(ThreadManager::mutex, 1000);
SetEvent(ts->threadEvent);
ReleaseMutex(ThreadManager::mutex);
}
return 0;
}
ThreadStruct::ThreadStruct(size_t opIndex)
{
this -> pi = 0;
this -> operationIndex = opIndex;
}
My Idea was that there will be an auto-reset event for each thread, which is set to signaled when a thread finishes it's computation. Main thread is waiting on one of thread Events to signal, and after modifying some values in a shared ThreadStruct (to enable thread start another portion of computations) it sets that same event to signaled, which is received by the exact same thread and the process received. But this doesn't work for even one thread: as a result i see values which are pretty random and not close to Pi (like 0.0001776328265).
Though my GDB debugger was working poorly (not displaying some variables and sometimes even crashing), I noticed that there were too much computations happening (I scaled down N to 1000. Therefore, I should have seen threads printing out "computing" 1000/40 = 25 times, but actually it happened hundreds of times)
Then I tried adding a mutex so threads wait until main thread is not busy before signaling the event. That made computation much slower, and still inaccurate and random (example: 50.26492171 in case of 16 threads).
What can be the problem? Or, if it's completely wrong, how do I organize multithread calculation then? Was creating a class a bad idea?
If you want to reproduce the problem, here is header file content (I am using c 20, MinGW 6.0):
#ifndef MULTITHREADPI_THREADMANAGER_H
#define MULTITHREADPI_THREADMANAGER_H
#include <iostream>
#include <vector>
#include <list>
#include <windows.h>
#include <memory>
struct ThreadStruct
{
size_t operationIndex;
long double pi;
HANDLE threadEvent = nullptr;
explicit ThreadStruct(size_t opIndex);
};
class ThreadManager
{
public:
explicit ThreadManager(size_t threadCount);
double run();
~ThreadManager();
private:
std::vector<ThreadStruct*> threadInfo;
std::vector<HANDLE> threads;
std::vector<HANDLE> threadEvents;
static HANDLE mutex;
static long double calc(size_t startIndex);
static const int OP_COUNT = 40;
static const int N = 100000000;
static DWORD WINAPI threadFunc(ThreadStruct* ts);
};
#endif //MULTITHREADPI_THREADMANAGER_H
To execute code, just construct ThreadManager with desired number of threads as argument and call run() on it.
CodePudding user response:
Even with all below changed, it doesn't give consistent values close to PI. There must be more stuff to fix. I think it has to do with the events. If I understand it correctly, there are two different things the mutex protects. And the event is also used for 2 different things. So both change their meaning during execution. This makes it very hard to think it through.
1. Timeouts
WaitForMultipleObjects may run into a timeout. In that case it returns WAIT_TIMEOUT, which is defined as 0x102 or 258. You access the threadInfo vector with that value without bounds checking. You can use at(n) for a bounds-checked version of [n].
You can easily run into a 10 second timeout when debugging or when setting OP_COUNT to high numbers. So, maybe you want to set it to INFINITE instead.
This leads to all sorts of misbehavior:
- the threads information (
operationIndex) is updated while the thread might work on it. operations_doneis updated although those operations may not be done- The mutex is probably overreleased
2. Limit the number of threads
The thread manager should also check the number of threads, since you can't set it to a number higher than MAXIMUM_WAIT_OBJECTS, otherwise WaitForMultipleObjects() won't work reliably.
3. Off by 1 error
Should be
size_t operations_done = (threads.size()-1) * OP_COUNT;
or
threadInfo[index] -> operationIndex = operations_done; // was OP_COUNT
otherwise it'll skip one batch
4. Ending the threads
Ending the threads relies on the timeouts.
When you replace all timeouts by INFINITE, you'll notice that your threads never end. You need another ReleaseMutex(mutex); before
res_pi /= N;
CodePudding user response:
struct CommonData;
struct ThreadData
{
CommonData* pData;
ULONG index, i, k;
ThreadData(CommonData* pData, ULONG index, ULONG i, ULONG k)
: pData(pData), index(index), i(i), k(k) {}
static ULONG CALLBACK Work(void* p);
};
struct CommonData
{
HANDLE hEvent = 0;
LONG dwActiveThreadCount = 1;
ULONG N;
double res[];
void* operator new(size_t s, ULONG m)
{
return LocalAlloc(LMEM_FIXED | LMEM_ZEROINIT, s m * sizeof(double));
}
void operator delete(void* p)
{
LocalFree(p);
}
CommonData(ULONG N) : N(N) {}
~CommonData()
{
if (HANDLE h = hEvent)
{
CloseHandle(h);
}
}
void DecThread()
{
if (!InterlockedDecrement(&dwActiveThreadCount))
{
if (!SetEvent(hEvent)) __debugbreak();
}
}
BOOL AddThread(ULONG index, ULONG i, ULONG k)
{
InterlockedIncrementNoFence(&dwActiveThreadCount);
if (ThreadData* ptd = new ThreadData(this, index, i, k))
{
if (HANDLE hThread = CreateThread(0, 0, ThreadData::Work, ptd, 0, 0))
{
CloseHandle(hThread);
return TRUE;
}
delete ptd;
}
DecThread();
return FALSE;
}
BOOL Init()
{
return 0 != (hEvent = CreateEvent(0, 0, 0, 0));
}
void Wait()
{
DecThread();
if (WaitForSingleObject(hEvent, INFINITE) != WAIT_OBJECT_0) __debugbreak();
}
};
ULONG CALLBACK ThreadData::Work(void* p)
{
CommonData* pData = reinterpret_cast<ThreadData*>(p)->pData;
ULONG index = reinterpret_cast<ThreadData*>(p)->index;
ULONG i = reinterpret_cast<ThreadData*>(p)->i;
ULONG k = reinterpret_cast<ThreadData*>(p)->k;
delete p;
ULONG N = pData->N;
double pi = 0;
do
{
double xi = (i 0.5) / N;
pi = 4 / (1 xi*xi);
} while (--k);
pData->res[index] = pi;
pData->DecThread();
return 0;
}
double calc_pi(ULONG N)
{
double pi = 0;
SYSTEM_INFO si;
GetSystemInfo(&si);
if (ULONG m = si.dwNumberOfProcessors)
{
if (CommonData* cd = new(m) CommonData(N))
{
if (cd->Init())
{
ULONG k = (N m - 1) / m, i = 0;
do
{
if (!cd->AddThread(m - 1, i, k))
{
break;
}
} while (i = k, --m);
cd->Wait();
if (!m)
{
double* pres = cd->res;
do
{
pi =*pres ;
} while (--si.dwNumberOfProcessors);
pi /= N;
}
}
delete cd;
}
}
return pi;
}
calc_pi(100000000); // 3.1415926535898149