I have a data frame where I want to sum column values with the same prefix to produce a new column. My current problem is that it's not taking into account my group_by variable and returning identical values. Is part of the problem the .cols variable I'm selecting in the across function?
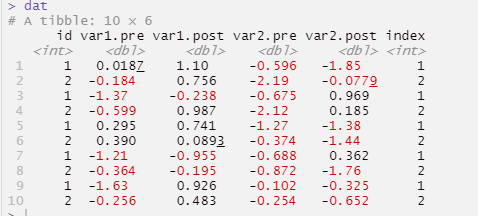
Sample data
library(dplyr)
library(purrr)
set.seed(10)
dat <- data.frame(id = rep(1:2, 5),
var1.pre = rnorm(10),
var1.post = rnorm(10),
var2.pre = rnorm(10),
var2.post = rnorm(10)
) %>%
mutate(index = id)
var_names = c("var1", "var2")
What I've tried
sumfunction <- map(
var_names,
~function(.){
sum(dat[glue("{.x}.pre")], dat[glue("{.x}.post")], na.rm = TRUE)
}
) %>%
setNames(var_names)
dat %>%
group_by(id) %>%
summarise(
across(
.cols = index,
.fns = sumfunction,
.names = "{.fn}"
)
) %>%
ungroup
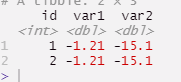
Desired output
CodePudding user response:
Whenever operations across multiple columns get complicated, we could pivot:
library(dplyr)
library(tidyr)
dat %>%
pivot_longer(-c(id, index),
names_to = c(".value", "name"),
names_sep = "\\.") %>%
group_by(id) %>%
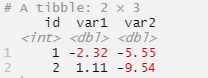
summarise(var1 = sum(var1), var2=sum(var2))
id var1 var2
<int> <dbl> <dbl>
1 1 -2.32 -5.55
2 2 1.11 -9.54
CodePudding user response:
For this and similar problems I made the 'dplyover' package (it is not on CRAN). Here we can use dplyover::across2() to loop over two series of columns, the first all columns ending with "pre" and second all columns ending with "post". To get the names correct we can use .names = "{pre}" to get the common prefix of both series of columns.
library(dplyr)
library(dplyover) # https://timteafan.github.io/dplyover/
dat %>%
group_by(id) %>%
summarise(across2(ends_with("pre"),
ends_with("post"),
~ sum(c(.x, .y)),
.names = "{pre}"
)
)
#> # A tibble: 2 × 3
#> id var1 var2
#> <int> <dbl> <dbl>
#> 1 1 -2.32 -5.55
#> 2 2 1.11 -9.54
Created on 2022-12-14 with reprex v2.0.2