I want to set the value of a list of columns (columns),to the value of another column (share), of a dataframe.
For this I wrote the following piece of code that does this:
for column in columns:
df_return = df.withColumn(column, F.lit(df.share) )
This only updates the last column of the list. If instead of df_return is df the code works but I want to know:
if it is possible to implement this without changing the initial dataframe?
is there a simpler way/more efficient way of replicating one column's values to multiple others?
CodePudding user response:
You can use select statement with list comprehension.
keep_cols = ['share', 'some_col']
columns = ['col1', 'col2', 'col3']
df_return = df.select(*keep_cols, *[F.col('share').alias(x) for x in columns])
CodePudding user response:
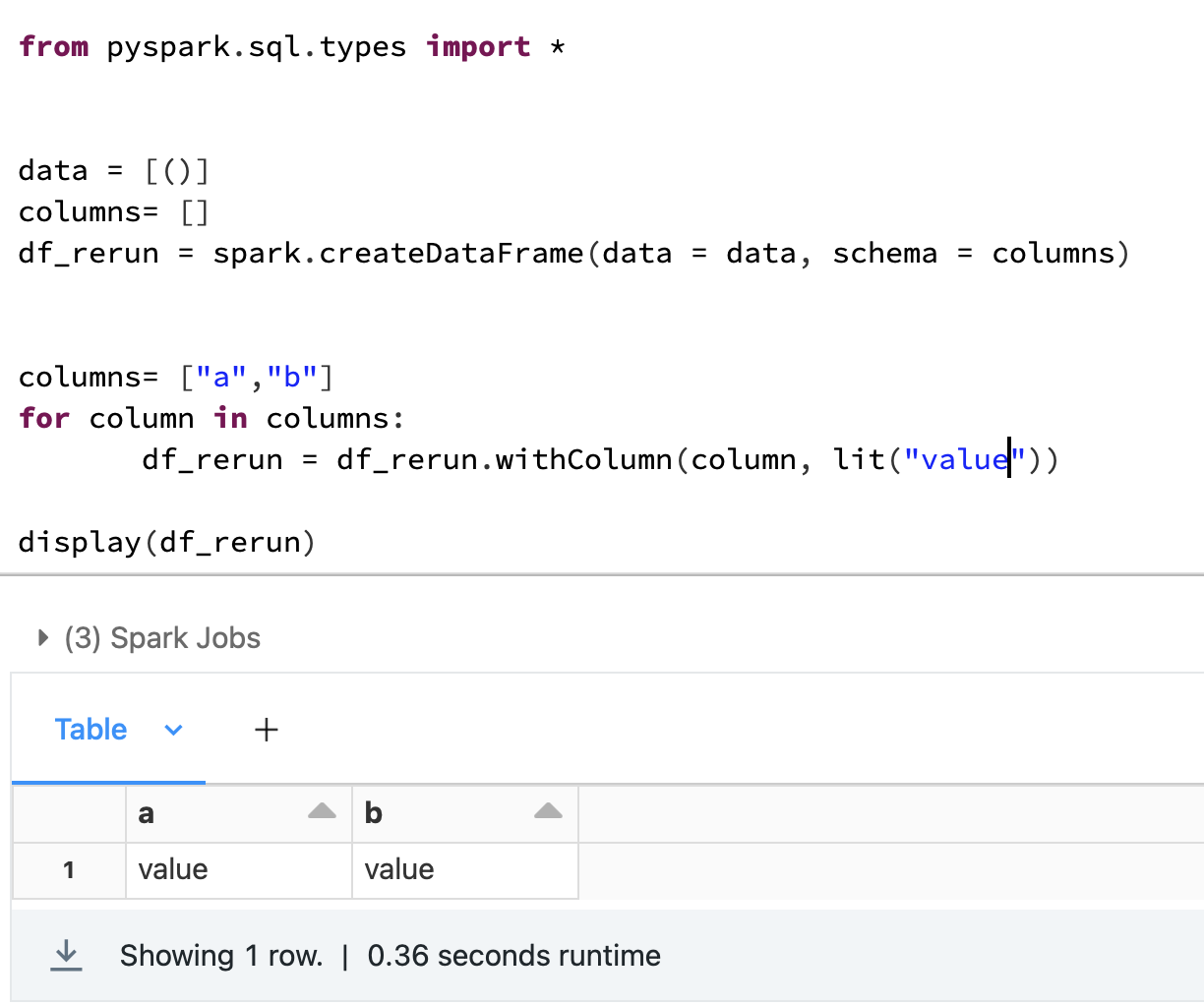
Just need to create an empty dataframe and then name the dataFrame as the result
data = [()]
columns= []
df_rerun = spark.createDataFrame(data = data, schema = columns)
for column in columns:
df = df.withColumn(column, F.lit(df.share) )
If you want to keep the original df as it is:
Quick example in Databricks here