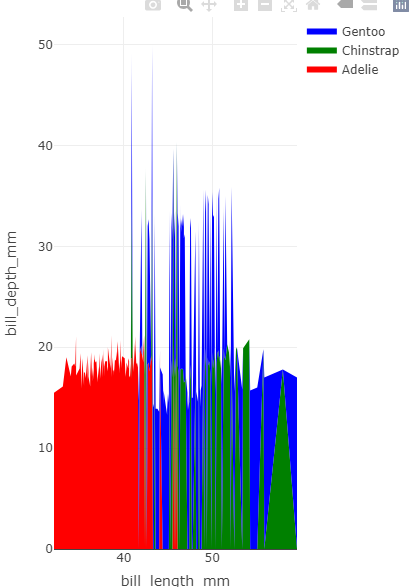
can you get both custom colours and factor order in plotly stacked area graphs?
e.g. the code below produces the right order but the wrong colours.
library(tidyverse)
library(plotly)
library(palmerpenguins)
penguins_cols <- c("Adelie" = "blue",
"Gentoo" = "red",
"Chinstrap" = "green")
penguin_order <- c("Gentoo", "Adelie", "Chinstrap")
df <- penguins %>%
mutate(species = factor(species, levels = penguin_order)) %>%
arrange(species)
plot_ly(df) %>%
add_trace(x = ~bill_length_mm,
y = ~bill_depth_mm,
name = ~species,
fillcolor = ~penguins_cols[species],
mode = "none",
type = "scatter",
stackgroup = 'one')
This is related to my previous question: 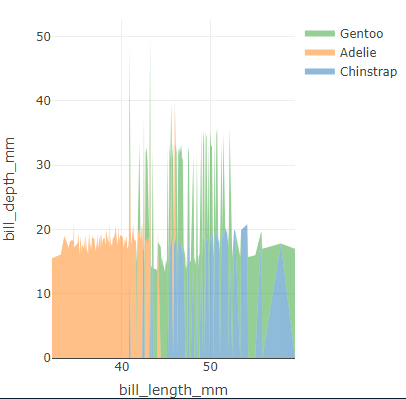
Real data added with some testing from @Kat's answer:
# data ---------------------------------------------
library(tidyverse)
library(plotly)
library(lubridate)
# factor levels
analyte_short_levels <- c("PCE", "TCE", "cis-1,2-DCE", "1,1-DCE", "trans-1,2-DCE", "Vinyl Chloride", "Ethene", "Ethane", "Acetylene", "Chloride")
# data
df <- tibble::tribble(
~analyte_short, ~SAMPLE_DATE, ~REPORT_RESULT_VALUE, ~molar_mass, ~value,
"1,1-DCE", "2019-10-05", 0.23, 96.94387817, 0.00237250669502487,
"1,1-DCE", "2020-06-02", 0.23, 96.94387817, 0.00237250669502487,
"1,1-DCE", "2020-09-12", 0.23, 96.94387817, 0.00237250669502487,
"1,1-DCE", "2021-04-24", 0.23, 96.94387817, 0.00237250669502487,
"1,1-DCE", "2021-08-25", 0.23, 96.94387817, 0.00237250669502487,
"1,1-DCE", "2022-05-04", 0.24, 96.94387817, 0.00247565916002595,
"Acetylene", "2019-10-05", NA, NA, 0,
"Acetylene", "2020-06-02", NA, NA, 0,
"Acetylene", "2020-09-12", NA, NA, 0,
"Acetylene", "2021-04-24", 0.73, 26.036, 0.0280381010907974,
"Acetylene", "2021-08-25", NA, NA, 0,
"Acetylene", "2022-05-04", NA, NA, 0,
"cis-1,2-DCE", "2019-10-05", 0.15, 96.94387817, 0.00154728697501622,
"cis-1,2-DCE", "2020-06-02", 0.23, 96.94387817, 0.00237250669502487,
"cis-1,2-DCE", "2020-09-12", 0.15, 96.94387817, 0.00154728697501622,
"cis-1,2-DCE", "2021-04-24", 0.15, 96.94387817, 0.00154728697501622,
"cis-1,2-DCE", "2021-08-25", 0.15, 96.94387817, 0.00154728697501622,
"cis-1,2-DCE", "2022-05-04", 0.4, 96.94387817, 0.00412609860004325,
"Ethane", "2019-10-05", NA, NA, 0,
"Ethane", "2020-06-02", NA, NA, 0,
"Ethane", "2020-09-12", NA, NA, 0,
"Ethane", "2021-04-24", 0.57, 30.068, 0.0189570307303445,
"Ethane", "2021-08-25", NA, NA, 0,
"Ethane", "2022-05-04", NA, NA, 0,
"Ethene", "2019-10-05", NA, NA, 0,
"Ethene", "2020-06-02", NA, NA, 0,
"Ethene", "2020-09-12", NA, NA, 0,
"Ethene", "2021-04-24", 0.4, 28.052, 0.0142592328532725,
"Ethene", "2021-08-25", NA, NA, 0,
"Ethene", "2022-05-04", NA, NA, 0,
"PCE", "2019-10-05", 5.7, 165.8339996, 0.0343717212016154,
"PCE", "2020-06-02", 5.2, 165.8339996, 0.0313566579383158,
"PCE", "2020-09-12", 5.6, 165.8339996, 0.0337687085489555,
"PCE", "2021-04-24", 9, 165.8339996, 0.0542711387393927,
"PCE", "2021-08-25", 6.8, 165.8339996, 0.0410048603808745,
"PCE", "2022-05-04", 8.4, 165.8339996, 0.0506530628234332,
"TCE", "2019-10-05", 15, 131.3889465, 0.114164854803825,
"TCE", "2020-06-02", 16, 131.3889465, 0.12177584512408,
"TCE", "2020-09-12", 14, 131.3889465, 0.10655386448357,
"TCE", "2021-04-24", 28, 131.3889465, 0.21310772896714,
"TCE", "2021-08-25", 17, 131.3889465, 0.129386835444335,
"TCE", "2022-05-04", 31, 131.3889465, 0.235940699927905,
"trans-1,2-DCE", "2019-10-05", 0.15, 96.94387817, 0.00154728697501622,
"trans-1,2-DCE", "2020-06-02", 0.15, 96.94387817, 0.00154728697501622,
"trans-1,2-DCE", "2020-09-12", 0.15, 96.94387817, 0.00154728697501622,
"trans-1,2-DCE", "2021-04-24", 0.15, 96.94387817, 0.00154728697501622,
"trans-1,2-DCE", "2021-08-25", 0.15, 96.94387817, 0.00154728697501622,
"trans-1,2-DCE", "2022-05-04", 0.21, 96.94387817, 0.0021662017650227,
"Vinyl Chloride", "2019-10-05", 0.1, NA, 0,
"Vinyl Chloride", "2020-06-02", 0.1, NA, 0,
"Vinyl Chloride", "2020-09-12", 0.1, NA, 0,
"Vinyl Chloride", "2021-04-24", 0.1, NA, 0,
"Vinyl Chloride", "2021-08-25", 0.1, NA, 0,
"Vinyl Chloride", "2022-05-04", 0.28, NA, 0
) %>%
mutate(SAMPLE_DATE = ymd(SAMPLE_DATE),
analyte_short = factor(analyte_short, levels = analyte_short_levels))
# named vector ----------------------------
colour_chlorinated <- c("PCE" = "#b60a1c",
"TCE" = "#e03531",
"cis-1,2-DCE" = "#ff684c",
"1,1-DCE" = "#e39802",
"trans-1,2-DCE" = "#f0bd27",
"Vinyl Chloride" = "#ffda66",
"Ethene" = "#309143",
"Ethane" = "#51b364",
"Acetylene" = "#8ace7e")
# graph but order incorrect ---------------------
plot <- plot_ly(data = df) %>%
add_trace(x = ~SAMPLE_DATE,
y = ~value,
name = ~analyte_short,
fillcolor = ~colour_chlorinated[analyte_short],
mode = "none",
stackgroup = 'one')
plot
# edited version of Kat's answer --------------------------
fixer <- function(plt) {
plt <- plotly_build(plt) # gather data for the plot
newOrd <- vector(mode = "integer") # list to store new data order
analyte_short_levels <- rev(levels(df$analyte_short)) # the order you're looking for in reverse
invisible(lapply(
1:length(plt$x$data),
function(j) {
nm <- plt$x$data[[j]]$name # get the name of the trace
newOrd[j] <<- which(analyte_short == nm) # get correct index position
}))
plt$x$data <- list(plt$x$data[[newOrd[1]]],
plt$x$data[[newOrd[2]]],
plt$x$data[[newOrd[3]]],
plt$x$data[[newOrd[4]]],
plt$x$data[[newOrd[5]]],
plt$x$data[[newOrd[6]]],
plt$x$data[[newOrd[7]]],
plt$x$data[[newOrd[8]]],
plt$x$data[[newOrd[9]]])
plt # return the updated plot
}
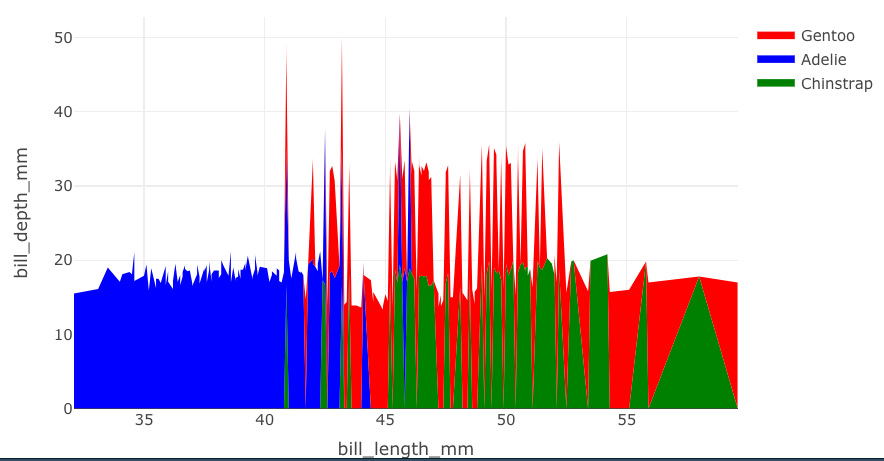
plot %>%
fixer() # blank
# fixer2 - same as Kat's fixer2() but diff column names and more in update plot-------------------------
fixer2 <- function(plt) {
plt <- plotly_build(plt)
newOrd <- vector(mode = "integer") # list to store new data order
# the order you're looking for in reverse
analyte_short <- rev(levels(df$analyte_short)) # <--- this changed
invisible(lapply(
1:length(plt$x$data),
function(j) {
nm <- plt$x$data[[j]]$name # get the name of the trace
newOrd[j] <<- which(analyte_short == nm) # get correct index position
}))
plt$x$data <- list(plt$x$data[[newOrd[1]]], # update plot
plt$x$data[[newOrd[2]]],
plt$x$data[[newOrd[3]]],
plt$x$data[[newOrd[4]]],
plt$x$data[[newOrd[5]]],
plt$x$data[[newOrd[6]]],
plt$x$data[[newOrd[7]]],
plt$x$data[[newOrd[8]]],
plt$x$data[[newOrd[9]]])
plt # return the updated plot
}
plot %>%
fixer2() # blank
# edited version of Kat's fixer2() -----------------
fixer3 <- function(plt, df, factor_column) {
plt <- plotly_build(plt)
newOrd <- vector(mode = "integer") # list to store new data order
# the order you're looking for in reverse
order <- rev(levels(df[[factor_column]])) # <--- this changed
invisible(lapply(
1:length(plt$x$data),
function(j) {
nm <- plt$x$data[[j]]$name # get the name of the trace
newOrd[j] <<- which(order == nm) # get correct index position
}))
plt$x$data <- list(map(1:length(unique(df[[factor_column]])), ~plt$x$data[[newOrd[.x]]]))
plt # return the updated plot
}
plot %>%
fixer3(df, "analyte_short") # doesn't work
CodePudding user response:
I thought I would just check...but I was sure making it an ordered factor was the answer...but it wasn't. So odd. I tried several things, but none worked.
I was able to create a workaround. I've added several comments to this UDF to explain a bit of what it's doing.
fixer <- function(plt) {
plt <- plotly_build(plt) # gather data for the plot
newOrd <- vector(mode = "integer") # list to store new data order
species <- rev(levels(df$species)) # the order you're looking for in reverse
invisible(lapply(
1:length(plt$x$data),
function(j) {
nm <- plt$x$data[[j]]$name # get the name of the trace
newOrd[j] <<- which(species == nm) # get correct index position
}))
plt$x$data <- list(plt$x$data[[newOrd[1]]], # update plot
plt$x$data[[newOrd[2]]],
plt$x$data[[newOrd[3]]])
plt # return the updated plot
}
This is how you use it.
plot_ly(df) %>%
add_trace(x = ~bill_length_mm,
y = ~bill_depth_mm,
name = ~species,
fillcolor = ~penguins_cols[species],
mode = "none",
type = "scatter",
stackgroup = 'one') %>%
fixer() # <<<----- I'm new!
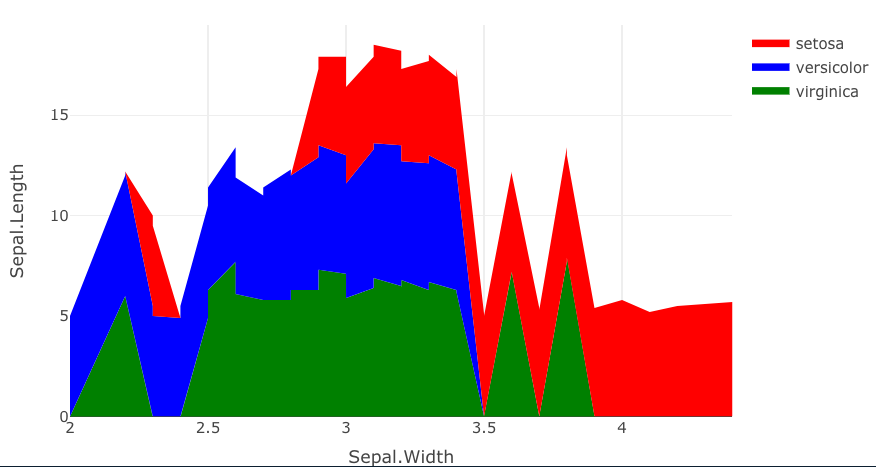
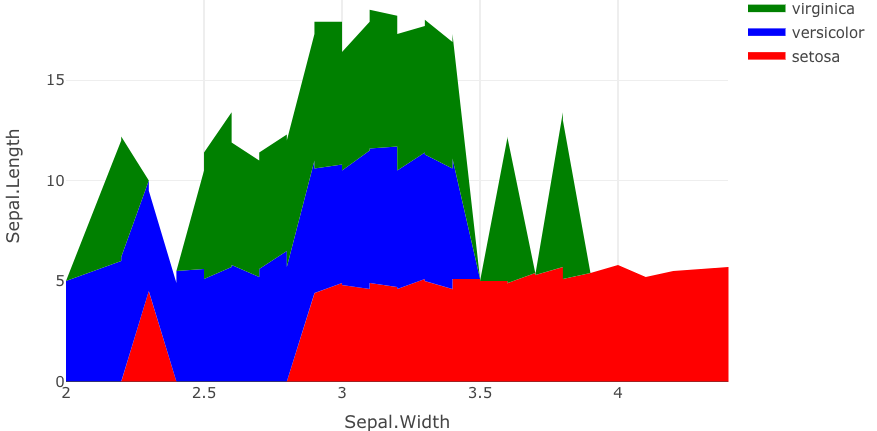
I thought that penguins is probably not the data you're really working with, so here's another demonstration of this same concept with the iris data using the same structure you used for penguins.
plot_ly(iris) %>%
add_trace(x = ~Sepal.Width,
y = ~Sepal.Length,
name = ~Species,
fillcolor = ~c("versicolor" = "red",
"setosa" = "blue",
"virginica" = "green")[Species],
mode = "none",
type = "scatter",
stackgroup = 'one')
I've made a single change to the UDF and updated the function name to fixer2. That change is marked in the comments.
fixer2 <- function(plt) {
plt <- plotly_build(plt)
newOrd <- vector(mode = "integer") # list to store new data order
# the order you're looking for in reverse
species <- rev(levels(iris$Species)) # <--- this changed
invisible(lapply(
1:length(plt$x$data),
function(j) {
nm <- plt$x$data[[j]]$name # get the name of the trace
newOrd[j] <<- which(species == nm) # get correct index position
}))
plt$x$data <- list(plt$x$data[[newOrd[1]]], # update plot
plt$x$data[[newOrd[2]]],
plt$x$data[[newOrd[3]]])
plt # return the updated plot
}
The new plot:
plot_ly(iris) %>%
add_trace(x = ~Sepal.Width,
y = ~Sepal.Length,
name = ~Species,
fillcolor = ~c("versicolor" = "red",
"setosa" = "blue",
"virginica" = "green")[Species],
mode = "none",
type = "scatter",
stackgroup = 'one') %>%
fixer2()