I.Text
A. Sub-section 1: This text
B. Sub-section 2: This text
C. Sub-section 3: This text
II. text
A. Sub-section 1: This text
B. Sub-section 2: This text
III. text
A.Sub-section 1: This text
i was expecting that i could extract the text after sub-section and add those into an array
The input is a long string
any solution will be nice with regex or string manipulation anything
CodePudding user response:
If you have all texts in a single variable, you can first use 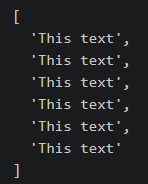
// multiline text
let text = `I.Text
A. Sub-section 1: This text
B. Sub-section 2: This text
C. Sub-section 3: This text
II. text
A. Sub-section 1: This text
B. Sub-section 2: This text
III. text
A.Sub-section 1: This text`,
// get Sub-section parts until end of line
sub_sections = text.match( /Sub-section\s?\d :[^\n]*/gi ),
// get only text of Sub-section
output = sub_sections.map( sub =>
sub.replace( /Sub-section\s?\d :/i, "" ).trim()
)
console.log( output )
CodePudding user response:
Your question is not well defined. Here is a solution making these assumptions:
- you have lines with sections with header and sub-sections
- sub-sections have leading spaces
- you want to extract the text after
:colon, and the text before and after the colon may vary - the result should be an array of all subsection text after the colon
const input = ` I.Text
A. Sub-section 1: This text I.A
B. Sub-section 2: This text I.B
C. Sub-section 3: This text I.C
II. text
A. Sub-section 1: This text II.A
B. Sub-section 2: This text II.B
III. text
A.Sub-section 1: This text III.A
`;
const regex = /^ .*?: *(. )/gm;
const result = [...input.matchAll(regex)].map(m => m[1]);
console.log(result);Output:
[
"This text I.A",
"This text I.B",
"This text I.C",
"This text II.A",
"This text II.B",
"This text III.A"
]
Explanation of regex:
^-- start of line.*?:-- non-greedy scan for first colon*-- optional space(. )-- capture group 1: everything to end of line with at least one chargm-- flags to macth multiple, and to treat start/end of line as start/end of string- the regex can be tweak as needed in case the assumptions are not correct